If you’ve ever visited a site like amiunique.org, browserleaks.com, or pixelscan.net, you’ve probably seen a warning about how “unique” your browser fingerprint is, often followed by a long list of technical attributes related to your browser and your IP address. These tools have become popular among privacy-conscious users, developers, and researchers trying to understand how exposed their browser really is.
But what do these tools actually measure? Are they accurate reflections of how websites track users or detect bots? And more importantly, what do they miss?
This article breaks down what browser fingerprinting test sites really do, how to interpret the results they show, and why many common assumptions, like “uniqueness equals trackability” or “spoofing makes me private”, don’t necessarily hold up in real-world systems. We’ll also look at where these tools fall short, what real tracking systems care about, and how to protect your privacy without accidentally making yourself more visible.
Because while it's natural to reach for tools that claim to hide your fingerprint, aggressive countermeasures can backfire. If you lie too much, or create a profile that looks unnatural or inconsistent, you may:
- Become more trackable, because the way you spoof can itself become a fingerprint
- Trigger stricter security checks, like CAPTCHAs, login friction, or outright blocks
In short: privacy is important, but deception isn't always the answer. A better strategy is understanding how detection works and making smart, consistent choices that protect you without drawing unwanted attention.
TL;DR
- Fingerprinting tools like Amiunique and Browserleaks expose surface-level data. They’re useful for education, but don’t fully reflect how fingerprinting is used in practice.
- A “unique” fingerprint doesn’t mean you can be tracked. What matters more is how consistent and stable your setup is across time and sessions.
- Spoofing or randomizing fingerprint signals often makes you more detectable, not less, especially if it introduces inconsistencies.
- Real-world tracking and fraud detection rarely rely on fingerprinting alone. They combine multiple signals like IP, cookies, and login behavior.
- If you care about privacy, focus on realism and stability. Avoid tools that lie about your device or inject noise unless you understand the trade-offs.
What these fingerprinting tools actually reveal
Browser fingerprinting test sites like amiunique.org, browserleaks.com, pixelscan.net, browserscan.net, and coveryourtracks.eff.org are designed to show users how much identifying information their browser leaks. Most follow the same model: collect JavaScript-based fingerprinting attributes, compute how “unique” you are in their sample, and display it as a proxy metric for trackability.
They’re useful for raising awareness, but they operate in a narrow context: a one-time, client-side snapshot of your browser’s environment. They don’t represent how fingerprinting is used in real-world tracking or fraud detection pipelines.
What kind of data do they collect?
Most of these tools use standard JavaScript APIs to extract properties from your browser. Typical data points include:
- Device and browser metadata
navigator.userAgent,navigator.platform,navigator.languages- Number of CPU cores via
navigator.hardwareConcurrency - Installed plugins and MIME types
- Display and hardware details
- Screen resolution and color depth (
window.screen) - GPU model and rendering quirks via WebGL
- Canvas fingerprint using
HTMLCanvasElement.toDataURL()
- Screen resolution and color depth (
- Network-related information
- Your IP address and inferred geolocation
- VPN or proxy usage (some use WebRTC or IP reputation checks)
- Advanced signals
- Audio fingerprinting using
OfflineAudioContext - Automation flags (e.g.
navigator.webdriver, missing APIs in headless browsers)
- Audio fingerprinting using
Here’s an example from browserleaks.com showing how canvas rendering can be used to extract a fingerprint:
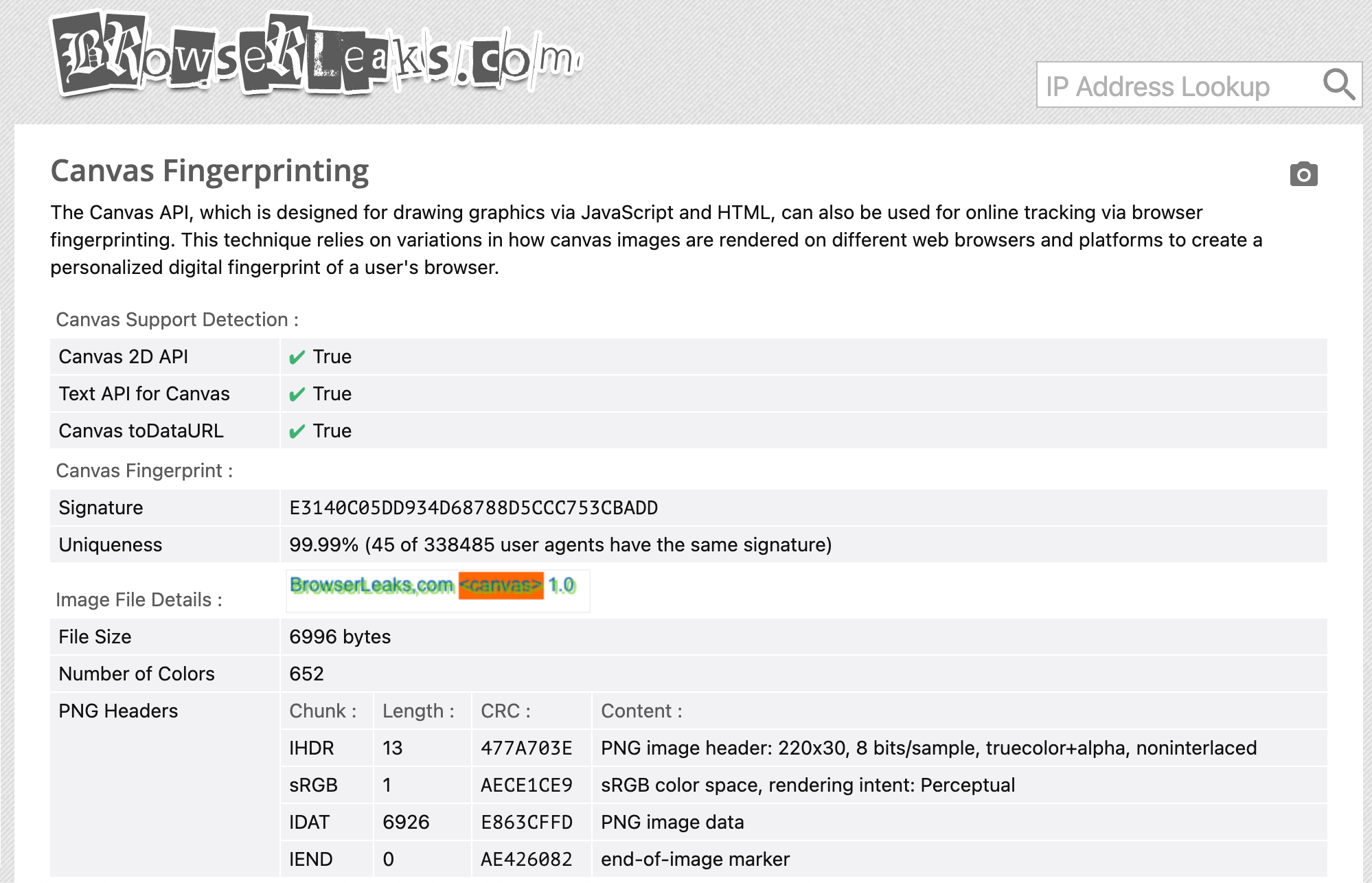
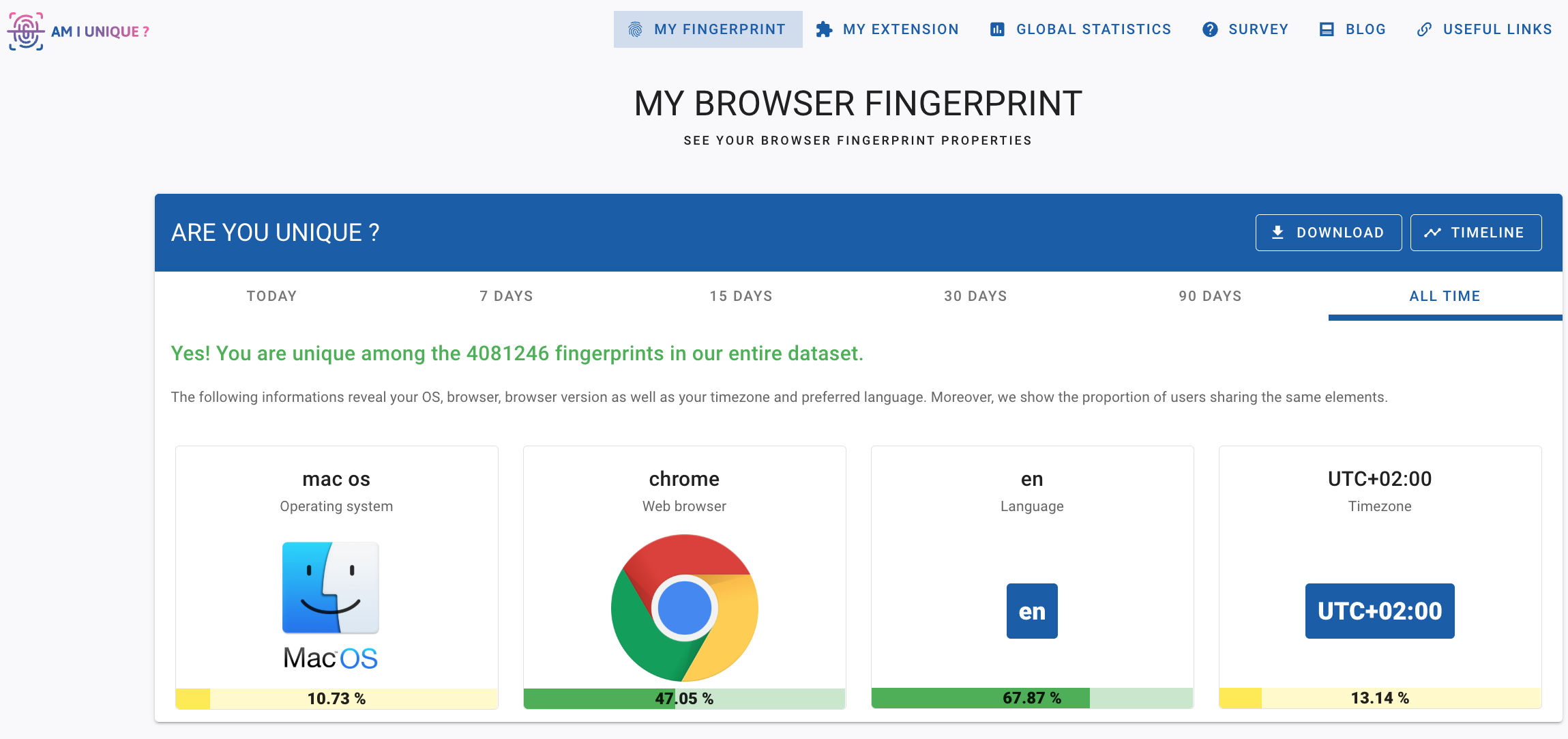
And below is a screenshot from amiunique.org, showing basic browser details and a uniqueness verdict:
What do they mean by “uniqueness”?
Most fingerprinting sites estimate how rare your fingerprint is within their own dataset. For example, Amiunique may say:
“Yes! You are unique among the 4,081,246 fingerprints in our entire dataset.”
This metric is based on the entropy of your fingerprint, essentially, how uncommon your combination of attributes is. But there are two important caveats:
- It’s relative to a small, skewed dataset. These sites attract a self-selected group of users, often developers or privacy enthusiasts, and the sample sizes are tiny compared to real web traffic. On large platforms with millions of users, fingerprint collisions are common, especially on devices like Chrome on Windows or Safari on iOS.
- Real-world systems rarely rely on entropy alone. Fingerprinting in the wild focuses more on consistency, coherence across signals, and how fingerprints evolve over time, not just how rare they are.
What these tools don’t do
While these tools are often interpreted as privacy diagnostics, they don’t reflect how modern detection systems operate:
❌ They don’t test stability across sessions or time, which is critical for tracking.
❌ They don’t evaluate coherence across fingerprint signals (e.g. whether GPU, OS, and user agent align).
❌ They don’t simulate scale, uniqueness among 100k users looks very different than among 100M.
❌ They don’t factor in cross-layer identifiers like cookies, local storage, IP address, or login behavior.
Worse, some test sites attempt to score fingerprint "authenticity" or "anomaly" without broad browser coverage. These systems often generate false positives on less common configurations, and maintaining an accurate fingerprinting suite at scale is difficult, especially for side projects that lack telemetry or broad web visibility.
In short, these tools are educational. They show what your browser reveals, but not how those signals are actually interpreted or used in real detection environments.
We’ll dive into those real-world misconceptions next.
Common misconceptions about fingerprinting
After running a few fingerprinting tests, it’s easy to draw the wrong conclusions, especially when you’re told your browser is “unique” or “highly identifiable”. But uniqueness is just one part of a much more complex system. Below are some of the most common misconceptions and why they fall apart in real-world scenarios.
Misconception #1: “If I’m unique, I can be tracked”
Not necessarily. Uniqueness only matters if it’s stable. A fingerprint that changes every visit, for example, due to a randomizer extension or subtle hardware shifts, might be unique each time, but not necessarily linkable over time.
Takeaway: Uniqueness ≠ trackability. Stability matters when it comes to tracking.
Misconception #2: “More attributes means a stronger fingerprint”
Not always. Adding more attributes only increases entropy if they’re statistically independent. In practice, many signals are correlated:
screen.widthandinnerWidthtypically scale together.- The user agent often overlaps with
navigator.platformand reported OS. - GPU model, canvas rendering, and WebGL outputs are tightly linked.
Simply adding redundant or low-variance attributes doesn’t improve fingerprint accuracy. However, these signals can still be valuable to uncover inconsistencies between attributes that are expected to align, especially when users attempt to spoof them.
Takeaway: Fingerprint quality depends on signal independence, not signal count.
Misconception #3: “Spoofing or randomizing fingerprint data protects me”
For real-world tracking systems, inconsistencies between signals, or deviations from known-good profiles, are often more revealing than entropy alone.
Research I presented at USENIX Security 2018 demonstrated that spoofing often introduces subtle anomalies, like mismatches between screen size and OS, or canvas output that doesn’t match GPU capabilities. These aren’t just detectable; they can actively amplify risk.
Once an inconsistency is detected, it can have several consequences. First, depending on how you spoof, the inconsistency itself may become a stable fingerprinting trait. If you consistently lie in the same way (for example, always spoofing your user-agent in combination with a misaligned screen resolution), that lie becomes trackable across sessions, even if your real setup isn’t. And since relatively few users spoof their environments, doing so — especially in a flawed or detectable way — makes you more identifiable, not less.
Second, you should know that fingerprinting is often used in security systems that protect websites. These systems often associate fingerprint inconsistencies with automation. Many bots forge fingerprints incorrectly, producing exactly the kinds of mismatches spoofers create. So when these signals are detected, you’re more likely to be flagged as a bot, subjected to stricter verification flows like CAPTCHAs, or blocked outright.
Misconception #4: “Changing my fingerprint regularly makes me harder to follow”
At first glance, rotating or randomizing your fingerprint might seem like a good way to break tracking. But unless it’s done carefully, it often causes more problems than it solves.
Indeed, while it may help to break tracking, it may significantly degrade your browser experience on websites that use fingerprinting for security purposes, e.g. to secure your account. From the perspective of a detection system, your fingerprint isn’t just used for tracking, it’s also used to evaluate whether your current behavior matches what’s expected for your session. If your fingerprint changes too frequently or in unrealistic ways (e.g., your OS or GPU changes mid-session), it can raise suspicion.
For example, if your session cookie stays the same but your fingerprint suddenly reflects a different OS or rendering engine, it violates basic assumptions about how real devices behave. This is exactly the kind of inconsistency that risk-based authentication systems are trained to catch, and it often results in:
- More frequent CAPTCHAs
- Secondary verification challenges
- Session invalidation or outright blocks
To be clear: rotating fingerprints can help reduce tracking only if the rest of your environment (session ID, IP, cookies) changes in sync, and if the spoofed fingerprint is coherent. But if the rotation introduces inconsistencies, as described in the previous section, it becomes a strong indicator of non-human behavior.
Takeaway: Changing your fingerprint too aggressively — or without aligning other signals — is more likely to break things than improve your privacy.
How to improve your browser privacy without breaking things
If spoofing and randomization tend to backfire, what should you actually do to protect your privacy?
The key is to stop thinking in terms of deception and instead focus on consistency, realism, and context-aware choices. The goal isn’t to disappear, it’s to avoid standing out.
✅ Use privacy-focused browsers, without modification
Stick to widely-used browsers that have fingerprinting protections built in, without trying to override or fake behavior.
Good choices include:
- Brave: Has strong defaults, including built-in fingerprinting defenses and ad/tracker blocking.
- Firefox: Offers Enhanced Tracking Protection and can enable
privacy.resistFingerprintingfor stricter behavior. - Safari: Especially on iOS, it's tightly locked down and behaves consistently across devices.
These browsers are used by millions of users. Staying within their default behaviors helps you blend in, which is much safer than trying to spoof your way to invisibility.
✅ Prioritize consistency over uniqueness
In addition to privacy considerations, having a consistent and stable fingerprint will avoid you a bad browsing experience, full of CAPTCHAs and block page/ Anti-bot and cybersecurity detection systems often flag users not because of any single unusual attribute, but because their profile feels off: values don’t align, or the setup changes too frequently in implausible ways.
Avoid:
- Randomizing fingerprinting attributes between sessions
- Faking OS-level details that contradict other signals (e.g., spoofed user-agent + real GPU)
- Using extensions that override fingerprint surfaces at the JavaScript level
Instead:
- Let your browser reflect your actual OS and hardware
- Keep your configuration stable across visits
- Minimize or avoid fingerprint-altering extensions unless you fully understand their side effects
A consistent, average-looking fingerprint, even if it's technically unique, is much less likely to trigger suspicion than one that's unstable or incoherent.
❌ Avoid spoofing extensions and anti-detect browsers
Many tools claim to increase privacy by modifying your fingerprint. In practice, they often create more problems:
- They introduce subtle inconsistencies that are easy to detect
- They mimic uncommon or outdated configurations
- They’re widely used by fraudsters — so just using one can increase your risk score
We've covered these risks in our reverse engineering of anti-detect browsers, and research on fingerprinting countermeasures shows how small implementation bugs can make spoofing detectable in practice.
If your goal is to reduce tracking or avoid false positives in bot detection systems, these tools usually hurt more than they help.
⚠️ Align your setup with your actual threat model
Not all fingerprinting is malicious. In many cases, it's used for:
- Bot detection (e.g. to block credential stuffing or automated scraping)
- Fraud prevention (e.g. matching logins to known devices)
- Security (e.g. detecting session hijacking or unusual access patterns)
Before you overhaul your setup, consider what you're trying to prevent:
- Do you want to reduce ad tracking?
- Avoid profiling by your ISP?
- Bypass bot detection?
Trying to defend against everything at once often leads to poor decisions — like stacking a VPN, user-agent spoofer, and canvas noise tool — which only makes you look suspicious.
A focused setup that aligns with your actual privacy goals is more effective and less likely to break things.
Why fingerprinting test sites don’t tell the full story
Sites like amiunique.org, browserleaks.com, and pixelscan.net are valuable for exploring how much data your browser exposes. They’re great educational tools — especially for understanding the building blocks of fingerprinting. But it’s important to recognize what they are not.
These sites operate in a very specific context: they capture a snapshot of your browser in a single session, compare it against their own (usually small and self-selected) dataset, and give you a “uniqueness” verdict. That’s informative, but it doesn’t reflect how fingerprinting is used at scale.
They don’t evaluate how your fingerprint behaves across sessions. They don’t test for internal consistency. They don’t model tracking across geographic cohorts or integrate cross-layer identifiers like cookies, login patterns, or IP data. Real detection systems are far more complex, and fingerprinting is just one of many signals.
Some sites even go further and attempt to assign a "fingerprint authenticity" or "anomaly" score. But these scores are only meaningful if they're calibrated at scale, across real-world browsers, operating systems, and usage patterns. Without that, they risk flagging perfectly normal setups as "fake" or "suspicious", especially on lesser-used platforms or browsers.
It’s also worth considering the incentives behind these tools. While projects like Amiunique and Cover Your Tracks are built by researchers and nonprofits, others promote anti-detect browsers, spoofing extensions, or proxies. These tools are often positioned as necessary for privacy, and the surrounding messaging tends to reinforce that by making fingerprinting feel scary by default.

But spoofing isn’t always required, and in many cases, it’s counterproductive. If not configured carefully, spoofing tools may introduce subtle inconsistencies that actually increase your detectability. And if your goal is simply to limit tracking or reduce exposure to ads and analytics, you don’t need to simulate a fake environment. Tools like Brave, Firefox, or Safari, paired with good content blocking, already provide strong protections.
Ultimately, the best strategy is to focus on realism, consistency, and fit-for-purpose privacy:
- Use well-maintained browsers with privacy-conscious defaults
- Don’t lie about your device or environment unless you have a specific reason
- Understand your threat model, and don’t overreact to “you are unique” warnings without context