

AI bots, AI scrapers, AI agents—you’ve seen these terms thrown around in product announcements, Hacker News posts, and marketing decks. But behind the hype, what do these bots actually do? And more importantly, how are they changing the fraud and bot detection landscape?
This article introduces the main types of bots emerging from the generative AI wave and explains why AI agents, in particular, are forcing online businesses to rethink their detection strategies.
We’ll start with definitions and categories, then briefly explore how these bots impact risk and detection. In future posts, we’ll go deeper into how to detect and authenticate AI bots, especially AI agents.
What qualifies as an AI bot?
"AI bot" is an overloaded term that can refer to at least three distinct use cases:
- LLM scrapers/crawlers: bots that collect data to train large language models (LLMs)
- RAG/search bots: bots that retrieve live information during user interactions (e.g. for answering current event questions)
- AI agents: bots that perform actions on behalf of users, like navigating websites or making purchases
These three categories differ in purpose, architecture, and impact. For detection teams, it’s critical to distinguish between them because they show up differently in traffic logs, pose different risks, and require different defenses.
Who’s building these bots, and what are they building?
The companies shaping the AI bot landscape vary significantly in terms of what they build. Some focus on developing foundation models, large-scale language models trained on vast datasets, while others specialize in creating user-facing tools that leverage these models.
OpenAI and Anthropic are examples of companies that train their own LLMs (like GPT-4o or Claude) and also provide applications for end-users to interact with these models. Their products typically include a chat interface, which has become the dominant UX for LLMs today. OpenAI’s ChatGPT and Anthropic’s Claude serve as both user access points and integration hubs for other tools, including emerging AI agents like OpenAI’s Operator.
Other players, like Google and Mistral, also develop their own models. Google’s Gemini is deeply integrated into its existing ecosystem, while Mistral focuses on smaller, open-weight models and offers a lightweight chat frontend called “le Chat.” X (formerly Twitter) has taken a more productized approach with Grok, an in-platform assistant that leverages LLM technology but is tightly embedded within its social platform.
Perplexity stands out because it doesn’t train its own foundation models. Instead, it builds new ways to interact with existing ones, often using APIs from OpenAI or Anthropic. What sets Perplexity apart is its focus on augmenting model capabilities with real-time search and browsing (Comet), or tools that behave like AI agents. These innovations make third-party models more actionable in specific tasks, such as information retrieval or task automation.
It's important to understand not just who is behind these bots, but what they're building and why. Some companies deploy web crawlers to collect training data, others run retrieval APIs that fetch real-time information during user queries, and a few are developing autonomous agents that browse or transact on the web. Knowing their purpose helps you anticipate their behavior, assess the risk, and decide how to respond appropriately.
Categories of AI bots
1. LLM scrapers: training data collection at scale
Training a modern large language model (LLM) requires massive amounts of text data. While some of this data is sourced from public datasets like Common Crawl, many providers supplement it by scraping websites directly. This scraping is typically done by automated bots that crawl the web to collect training material, what we refer to as LLM scrapers.
Several major AI companies operate dedicated crawlers and provide documentation about their use. OpenAI, for instance, runs GPTBot, which is explicitly designed to retrieve public content that may be used in model training. Its user agent is:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.1; +https://openai.com/gptbotSimilarly, Anthropic’s ClaudeBot performs the same function, with a nearly identical user agent format:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)Perplexity, despite not training its own models, also operates a crawler, PerplexityBot, to power its AI-driven search engine. Its user agent looks like:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)Google remains an outlier here. While it does train foundation models and operates its well-known Googlebot for indexing the web, the extent to which this data is used for AI training is opaque. Google documents its common crawlers, but there's limited transparency on how this traffic is partitioned between traditional search and AI.
In theory, these declared scrapers offer website owners a way to opt out of model training, typically via robots.txt exclusions. In practice, though, this transparency is partial at best. Many AI companies likely rely on third-party data aggregators or operate secondary, undeclared bots that attempt to bypass detection.
This ambiguity poses challenges for bot detection and content governance. Blocking known scrapers like GPTBot or ClaudeBot ensures your content won’t be used directly in model training. That may be desirable from a privacy or monetization perspective, but it also means your brand or content might not be surfaced in future AI-generated outputs.
From a detection perspective, LLM scrapers generally don’t behave like malicious bots: they’re often rate-limited, well-behaved, and identifiable. But the decision to block them isn’t purely technical; it’s a policy choice. And if your detection system relies only on user agent strings or IP reputation, you may miss stealthier scrapers that operate outside these formal boundaries.
2. RAG and search bots: real-time retrieval on behalf of users
Large language models are static by design. Once trained, they can’t natively answer questions about recent events or dynamic topics like sports scores, breaking news, or flight statuses. To address this limitation, many AI platforms augment model responses with real-time web retrieval, a pattern known as Retrieval-Augmented Generation (RAG).
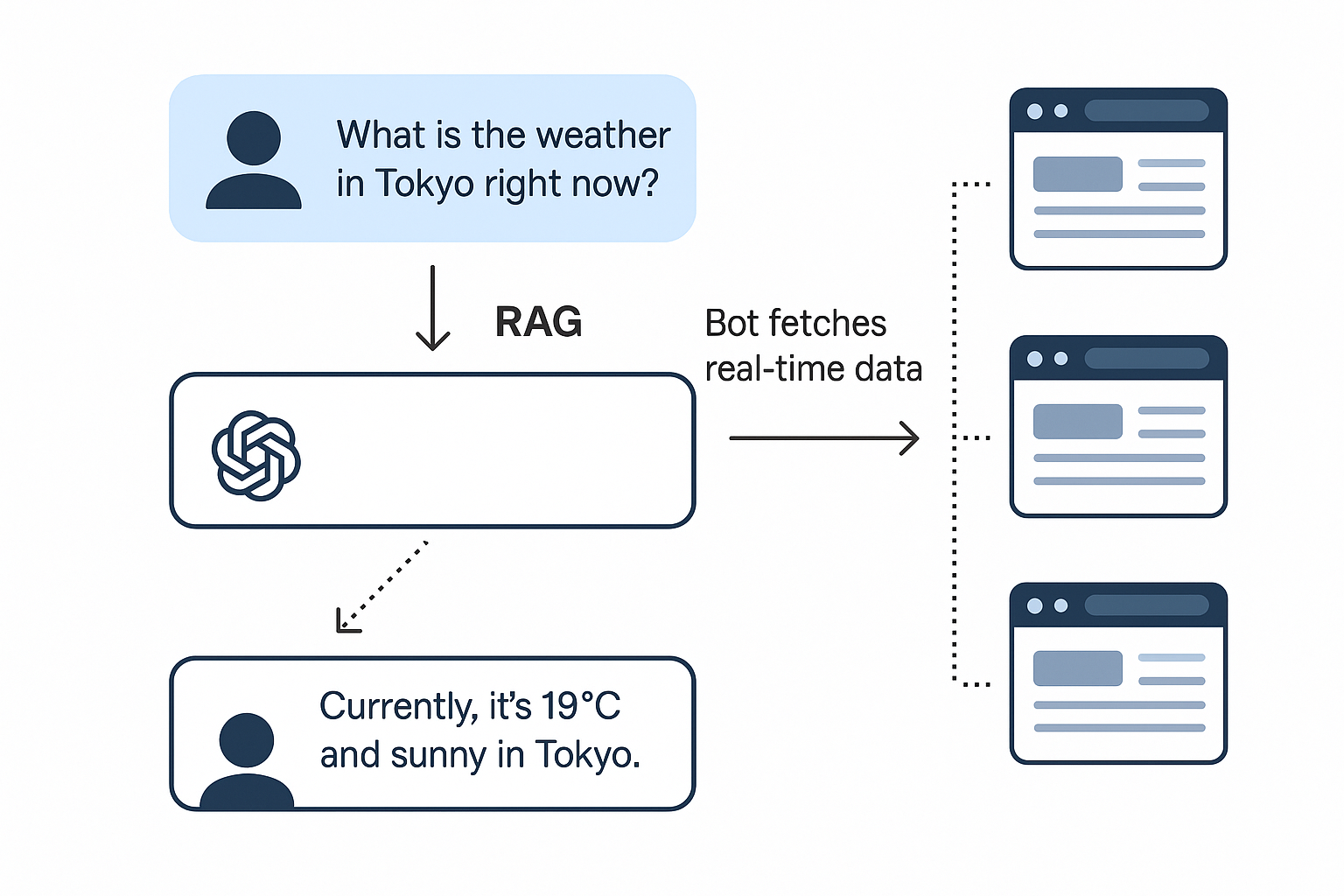
In a typical RAG flow, the system identifies gaps in the model’s knowledge during a user interaction. If the user asks, “What’s the weather in Tokyo right now?” the model itself can’t answer reliably from static training data. Instead, it delegates the task to a retrieval component, a bot that performs a live web request to fetch up-to-date information. The result is then passed back to the model, which incorporates it into a final, user-facing response.
These retrieval bots differ fundamentally from scrapers. They don’t crawl broad swaths of the web to build datasets. Instead, they act narrowly and on demand, often targeting a single page or API in response to a specific user query. That distinction matters both architecturally and for detection. The schema below provides a high-level overview of a RAG flow.
Major providers have introduced identifiable agents to handle this retrieval layer. For example, OpenAI uses a bot called ChatGPT-User during certain interactions in ChatGPT, especially when browsing features or custom GPTs are enabled. Its user agent is:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/botAnthropic has a similar agent—Claude-User—that appears in traffic when Claude fetches content to fulfill a user request. While these bots often include some level of documentation or metadata, transparency is inconsistent across vendors.
It’s worth noting that RAG bots are typically scoped to the context of a session. They don’t persistently store the retrieved content for future training, at least not officially. But depending on a company’s data retention policy, content accessed during free-tier usage could still influence model behavior through feedback loops or future fine-tuning.
For bot and fraud teams, the key distinction is this: RAG bots operate on behalf of a human. A user has asked a question, and the bot is executing a targeted fetch to answer it. Blocking this traffic might break legitimate functionality, especially for AI-powered search engines or assistants. At the same time, these bots can be difficult to distinguish from generic scraping or automation if you're only looking at traffic patterns or headers.
Detection decisions around RAG bots often come down to purpose and impact. If they access public content in low volumes, they may be benign or even beneficial. But if they overwhelm your endpoints or bypass usage limits, they may warrant rate-limiting or policy-based gating.
Understanding who the bot is acting for, and how frequently, is more important than simply knowing it’s automated. That nuance becomes even more important in the next category: bots that don’t just read, but act.
3. AI agents: bots that take action, not just read
Among all AI-driven bots, AI agents are the most disruptive for traditional detection systems. Unlike scrapers that passively read content or RAG bots that fetch information to answer questions, agents are designed to act. They don’t just observe the web, they interact with it on behalf of users.
A user might issue a natural language instruction like:
“Book me a flight to New York tomorrow.”
From there, the agent determines which website to use, fills out forms, clicks through navigation, and sometimes even completes a transaction. These systems perform tasks that historically required human effort or purpose-built scripts, except now, anyone can access them via a simple chat interface.
Architecturally, AI agents fall into two broad categories, each with distinct implications for detection.
Cloud-based agents run on infrastructure controlled by the AI provider. They operate within remote browser environments, allowing users to outsource automation to a managed backend. OpenAI’s Operator is a prime example: users describe a task in plain language, and Operator executes it inside a hosted browser. To reduce risk, the system is designed to prompt users to take over for sensitive steps like authentication or payment.
Skyvern offers a more aggressive model. It runs entirely in the cloud and focuses on fully autonomous workflows, including automated CAPTCHA bypass, without user involvement. This allows it to execute complete web flows without human intervention, raising concerns for anti-bot and anti-abuse systems.
Local agents, by contrast, run directly on the user’s device and automate interactions from within the user’s own browser. These tools often share the same execution context, network fingerprint, and session state as legitimate traffic, making them far harder to isolate.
A clear example is Perplexity’s Comet, a customized Chromium-based browser with an embedded AI assistant. Comet operates in two modes: passive Q&A, and active automation when tasks require it. Everything runs locally, on the same machine and browser session the user already uses to browse manually. From a detection perspective, this makes it nearly indistinguishable from human activity.
Critically, most AI agents, whether running in the cloud or locally, don’t expose their presence. They avoid obvious bot signals like custom user agent strings or navigator.webdriver = true, making them difficult to distinguish from legitimate browser traffic. Agents like Perplexity’s Comet are designed to blend in, and can often only be detected through indirect side effects such as DOM mutations or injected scripts. This stealth is deliberate. Bots built to bypass detection rarely self-identify.
As we’ll explore in the next article, user agent strings should never be used as the sole signal for authentication. They’re easy to forge and frequently abused by attackers. Reliable bot identification requires stronger signals, such as IP-based checks, reverse DNS lookups, or cryptographic authentication mechanisms.
From a fraud and bot mitigation perspective, this category poses the most acute challenges. AI agents increasingly automate high-risk workflows, account creation, login, checkout, that detection systems are trained to scrutinize. But their behavior may overlap with abuse patterns. A login initiated by an agent might resemble credential stuffing. A checkout flow could look like carding. Yet in many cases, these actions are legitimate, performed under user control.
This breaks the foundational assumptions of most detection pipelines. Automation is no longer inherently suspicious. The challenge now is understanding intent: who is the agent acting for, what is it trying to do, and is that behavior consistent with a real user’s goals?
The technical challenges around AI agents aren’t theoretical, they’re already showing up in detection pipelines. Cloud-based agents often reuse the same IP infrastructure across many users, making IP reputation noisy or meaningless. Local agents run inside the user's browser context, so their traffic inherits the same fingerprint and session as manual user activity. And most agents don’t expose any form of attestation or identity you can rely on.
The outcome is a familiar one: automation is getting easier to deploy, and harder to differentiate from abuse. Tasks that used to require engineering effort can now be performed with a one-line instruction, using tools that deliberately avoid detection.
This doesn’t just increase bot volume, it changes the nature of what automation looks like. Relying on static fingerprints, user agent checks, or automation heuristics isn’t enough. Detection needs to evolve toward context- and intent-based signals that help determine whether a request is part of normal user activity, or something else.
Why this matters for detection teams
The rise of AI bots, especially AI agents, forces a rethink of how we detect, categorize, and respond to automated traffic. Traditional bot mitigation systems have long operated on a set of binary assumptions: bots are bad, humans are good, and signals like IP addresses or user agents can reliably distinguish the two. That model no longer holds.
AI agents in particular expose the limitations of intent-blind detection. These bots may exhibit all the typical markers of automation, fast interactions, cloud-origin traffic, consistent browser fingerprints, but still be operating under a legitimate user’s direction. At the same time, attackers can leverage the exact same tools to launch credential stuffing, carding, or fake account creation at scale.
This creates ambiguity. Two login attempts might look identical from a network and fingerprint perspective, but one was triggered by a user asking an agent to help log in, while the other is part of a credential stuffing run. Without context, it’s nearly impossible to tell the difference.
Authentication becomes more difficult, too. Cloud-based agents often share IP infrastructure, which means you might see hundreds of users routed through a small pool of addresses. That breaks IP-based reputation and authentication models. Local agents introduce a different problem: they blend into user environments and may spoof their fingerprint or behave like browser extensions. Even when their presence is known, there’s rarely a standard way to validate who they’re acting for.
Worse, most AI agents today don’t offer strong signals of identity. They don’t present verifiable claims, device attestations, or proof of user delegation. That means fraud teams are left inferring trust from behavior, at the same time attackers are working to mimic legitimate workflows.
What this ultimately demands is a shift in detection philosophy. Teams need to go beyond static allowlists or fingerprint-based heuristics. Risk models must start reasoning about intent, delegation, and context, not just automation. That includes recognizing when a bot may be helping a real user, and when it’s operating autonomously to exploit your system.
Quick reference: how the categories compare
Not all AI bots are created equal. They differ in purpose, visibility, and impact, and each type introduces new considerations for security, privacy, or business operations.
| Category | Purpose | Example Bots | Why it matters |
|---|---|---|---|
| LLM scraper | Collect content to train models | GPTBot, ClaudeBot, PerplexityBot | Impacts whether your site content appears in future AI outputs or is monetized |
| RAG/search | Retrieve live data for answers | ChatGPT-User, Claude-User | Can surface your content in real-time responses; may affect usage and SEO |
| AI agent | Perform actions on behalf of users | Operator, Comet, Stagehand | Automates sensitive flows like login or checkout; challenges fraud assumptions |
As AI bots become more capable and more common, they’re forcing detection systems to move beyond binary decisions. The real challenge isn’t just identifying that automation is happening—it’s figuring out what type of bot you’re dealing with, what it’s doing, and whether that behavior aligns with your risk model.
In the next post, we’ll focus on how to detect and authenticate these bots, especially AI agents. We’ll cover the technical signals they emit (or try to suppress), why traditional detection often fails, and how defenders can adapt their systems to reason about context and intent.


