This is the second post in our series on AI bots and their impact on fraud and detection systems.
In the first article, we outlined the main categories of bots emerging from the generative AI ecosystem, explained their roles, and showed how each affects detection strategies. We grouped AI-driven automation into three broad categories:
- LLM scrapers or crawlers, which collect public content to train large language models
- RAG or search bots, which retrieve live data (like recent news or sports scores) during user queries
- AI agents, which perform actions on behalf of users, such as navigating a site, logging in, or completing purchases
All three categories show up in web traffic and may need to be handled differently depending on the use case. But from a fraud detection perspective, AI agents are by far the most disruptive. These bots don't just read, they act. And in many cases, they do so in ways that mimic legitimate users.
In this article, we focus on detection and authentication. We’ll look at how to identify each type of AI bot, what signals they expose (if any), and why AI agents in particular are difficult to detect or authenticate. We’ll start with scrapers and RAG bots, which are typically declared and easier to manage. Then we’ll go deeper into agent-based automation, where visibility is limited and intent is harder to infer.
While that’s not the main purpose of the article, we also include a detailed technical analysis of Perplexity Comet, a local AI agent that runs as a modified Chromium browser. By digging into the DOM and runtime behavior, we show how these agents can sometimes be detected through subtle side effects, despite having no exposed identity.
Detecting LLM scrapers and RAG bots
This section focuses on the first two types of AI bots introduced in the previous article:
- LLM scrapers, which crawl public websites to collect data used for training large language models
- RAG/search bots, which retrieve real-time content on demand to support user queries
These bots are typically well-behaved. Most vendors attach identifiable user agents, follow robots.txt rules, and in some cases publish their IP ranges. That gives detection teams a relatively straightforward path to identification and control.
Two common handling strategies
For scrapers that follow documented practices, you generally have two reliable options:
- User agent and IP matching: If the vendor provides both, you can use the combination to verify bot traffic and enforce policy: allow, block, throttle, or gate access depending on your use case.
- User agent plus robots.txt control: If no IP range is provided, don’t rely on the user agent alone. These can easily be spoofed by attackers. Instead, most large AI vendors honor
robots.txt, so using it to control crawler access is the safer and more robust option in that case.
It’s also worth noting that a new approach to bot authentication is emerging. As we’ll show in the next section, OpenAI has started using HTTP Message Signatures, a cryptographic standard proposed by Cloudflare to help verify the origin of automated requests. While adoption is still early, this could become an additional layer for authenticating bots in the future.
To ground this in practice, we’ll walk through a few representative examples of LLM scrapers from major AI vendors, how they identify themselves, what data they provide, and how you can verify or control their access.
OpenAI: GPTBot
OpenAI publishes detailed documentation for GPTBot, the crawler it uses to gather training data. It identifies itself with the following user agent and IP list:
User agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.1; +https://openai.com/gptbot
IP list: https://openai.com/gptbot.jsonYou can use both the user agent and IP list to authenticate requests and apply granular controls, for example:
- Allowing GPTBot on public pages but blocking it from user-generated content
- Restricting crawling to off-peak hours
- Rate-limiting if traffic volume spikes
Perplexity: PerplexityBot
Perplexity provides similar guidance through its bot documentation. Its crawler uses the following user agent and published IP range:
User agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot
IP list: https://www.perplexity.ai/perplexitybot.jsonAs with GPTBot, these identifiers can be used to enforce access policies confidently and reduce the risk of spoofing.
Note that both OpenAI and Perplexity operate multiple bots. The examples above reflect just one crawler per vendor. If you want to apply broader controls, refer to each provider’s full list of bot identifiers.
Anthropic: ClaudeBot
Anthropic explains its crawling behavior in this support article. Their scraper, ClaudeBot, identifies with this user agent:
User agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.comHowever, unlike OpenAI and Perplexity, Anthropic does not offer static IP ranges. Instead, they recommend using robots.txt to manage access.
They also support the non-standard Crawl-delay directive. Example configurations:
User-agent: ClaudeBot
Disallow: /User-agent: ClaudeBot
Crawl-delay: 1This allows you to opt out of crawling or reduce load without relying on weak identity signals.
Undeclared or non-compliant scrapers
Not all bots play by the rules. Some AI vendors, especially smaller or newer ones, may ignore robots.txt, rotate through residential IPs, or skip user agent disclosure entirely. These crawlers behave more like stealth bots and can’t be identified through documentation.
To detect them, you’ll need to rely on general scraping detection techniques:
- Fingerprint and headless browser detection
- Header and TLS consistency checks
- Behavioral analysis (crawl patterns, fetch rate, depth)
- IP risk scoring or threat intelligence feeds
Scrapers from major vendors are usually straightforward to manage, as long as they stick to their published metadata. For the rest, they fall into the same bucket as any unknown automation and need to be handled accordingly.
As we’ll see in the next section, some vendors like OpenAI are going further than just declaring their bots. They're adopting new authentication mechanisms like HTTP Message Signatures that may offer a more robust foundation for identifying bot traffic in the future. If the ecosystem moves in that direction, it could help detection teams better distinguish between legitimate AI usage and unwanted scraping.
Detecting AI agents
This section focuses on AI agents, bots that don’t just retrieve content, but interact with websites on behalf of users. These agents can automate benign workflows like navigation or scraping, but they can also perform sensitive actions like submitting forms, logging in, or completing purchases.
From a detection standpoint, agents are harder to classify than scrapers. Some run in the cloud, others run locally in the user's browser. Most don’t identify themselves, and many intentionally avoid detection through stealth techniques like fingerprint evasion and proxy rotation.
We analyzed four representative agents, covering both cloud-based and local deployments:
To help summarize what we’ve seen across the four agents, the table below compares their deployment model, whether they declare their presence, how easily they can be detected, and whether they offer any form of cryptographic authentication. This highlights the current gap between detection and reliable attribution in the AI agent ecosystem.
| Agent | Deployment | Self-identifies | Detectable via fingerprint/behavior | Cryptographically authenticated |
|---|---|---|---|---|
| OpenAI Operator | Remote | ✅ via headers | ✅ Slight JS fingerprint inconsistencies | ✅ via HTTP Message Signatures |
| Browserbase | Remote | ❌ | ✅ Playwright fingerprint | ❌ |
| Skyvern | Remote | ❌ | ✅ Subtle fingerprint (e.g. canvas, fonts) | ❌ |
| Perplexity Comet | Local | ❌ | ✅ DOM mutations, style overrides | ❌ |
We’ll walk through each one, starting with OpenAI, the only agent we tested that provides a verifiable identity via headers.
Detecting OpenAI’s agent mode
Unlike other agents in this review, OpenAI’s traffic includes a signed identity header. This is part of Web Bot HTTP Message Signatures, a proposed standard from Cloudflare that adds cryptographic headers to bot requests. These headers allow websites to verify the authenticity of bot traffic using public key infrastructure (PKI), without relying on spoofable attributes like user agent strings or IP blocks.
Here’s what a typical OpenAI request might include:
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36
Signature: sig1=:T00yyxrppTybFU2axZFORWQ8J/pq8Ug15l+9O4NKeBXyuU2fOV9Jqn0IrLZbzpBKyRd81loI917BV/8L84lfCw==:
Signature-Input: sig1=("@authority" "@method" "@path" "signature-agent");created=...;expires=...;keyid="..."...
Signature-Agent: "https://chatgpt.com"The Signature and Signature-Input headers allow servers to verify the request came from OpenAI infrastructure. The Signature-Agent field identifies the application issuing the request—in this case, ChatGPT.
From a browser fingerprinting perspective, OpenAI’s agent behaves like a normal headful Chrome session:
navigator.webdriveris not set- No Chrome DevTools Protocol (CDP) artifacts
- TLS and JavaScript environments match stock Chrome behavior
While there are minor inconsistencies, for example, navigator.platform might report differently in the main thread versus a web worker—these details are largely irrelevant. The important point is that OpenAI is explicitly declaring its presence through headers, and that makes fingerprint anomalies less important. If you trust the cryptographic signature, you can authenticate the request regardless of device quirks.
OpenAI is currently the only vendor we tested that supports this kind of standards-based attestation. If more AI agents adopt it, detection teams will have a much more reliable path to identifying and managing automated traffic.
This is still early-stage adoption, but it marks a potential shift away from fingerprint arms races and toward verifiable identity. For now, OpenAI is the exception—not the norm.
Detecting Browserbase (remote AI agent)
We tested Browserbase, a cloud-based automation platform that supports Playwright, Puppeteer, and Selenium. We used the developer plan, which includes a basic “stealth mode” designed to reduce bot visibility. This mode appears focused primarily on bypassing CAPTCHAs rather than full bot detection evasion.
Browserbase also advertises an advanced stealth mode available only to custom enterprise customers. We didn’t evaluate that tier. The goal here isn’t to benchmark evasion quality, but to understand whether Browserbase bots can be identified or attributed in practice, particularly when used as AI agents.
Here’s the script we used to launch a basic Playwright session through Browserbase:
import Browserbase from "@browserbasehq/sdk";
import { chromium } from "playwright-core";
const bb = new Browserbase({ apiKey: process.env.BROWSERBASE_API_KEY });
const session = await bb.sessions.create({
projectId: process.env.BROWSERBASE_PROJECT_ID,
});
const browser = await chromium.connectOverCDP(session.connectUrl);
const defaultContext = browser.contexts()[0];
const page = defaultContext.pages()[0];
await page.goto("https://deviceandbrowserinfo.com/info_device", {
waitUntil: "domcontentloaded",
});
const res = await page.evaluate(() => window.fingerprint);
console.log(res);
await page.screenshot({ fullPage: true, path: "basic-stagehand.png" });
await page.close();
await browser.close();We pointed the bot to a page running custom fingerprinting and bot detection scripts. Despite using stealth mode, the session was clearly detectable as an automated Playwright instance. Key signals included:
- Presence of Playwright-specific globals like
window.playwright__binding - Timezone set to
UTC, which is common in scripted environments - Inconsistencies between JavaScript contexts (e.g.
navigator.platformreportsMacin the main thread butLinuxin a worker) - A Chrome DevTools Protocol (CDP) leak, typical of Playwright and other CDP-based frameworks
navigator.webdriverwas not present, but this signal is now too weak to rely on in isolation
Overall, the session was easy to fingerprint as automation. What it didn’t offer was attribution. There was no way to tie this traffic specifically to Browserbase. From a detection standpoint, it looked like a generic bot running Playwright in the cloud.
Basic Browserbase sessions are detectable as automation, but the platform doesn’t self-identify, and attribution isn’t possible based on observable signals alone. Like most AI agents in the wild today, they are explicitly designed not to be recognizable.
This matters if your goal is not just detecting bots, but identifying whether a request comes from a known AI agent. Without cooperation from the platform, there’s no way to say “this traffic is coming from Browserbase” versus any other automation stack.
Note that we didn’t test their advanced stealth offering, which is likely more evasive. Given the team’s anti-detect background (including prior work on sneaker bots), it’s reasonable to assume that higher-tier clients get a stronger anti-detect layer.
Detecting Skyvern (remote AI agent)
The third AI agent we tested is Skyvern, a cloud-based automation platform with a strong emphasis on stealth and anti-bot capabilities. We subscribed to their cloud plan, which includes proxy management and evasion tooling designed to help bots avoid detection.
Unlike traditional automation tools where you write code to control the browser, Skyvern is more language-driven. We simply instructed the agent to visit a test page containing fingerprinting and bot detection scripts. This allowed us to analyze its behavior and client-side signals without needing to build a script.
The result was a fingerprint that was slightly unusual, but clean. Skyvern didn’t exhibit any obvious automation traits. Specifically:
navigator.webdriverwas not present- No Chrome DevTools Protocol (CDP) artifacts
- No inconsistencies between JavaScript contexts (e.g. main thread vs worker)
All requests were sent through high-quality US residential and ISP proxies, including IPs associated with AT&T. This makes IP reputation checks less effective and increases the chance the bot blends in with normal user traffic.
A few fingerprint details stand out:
- User agent:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0This mimics Microsoft Edge running on Ubuntu. It’s plausible, but not something you commonly see from typical end users. - WebGL renderer:
ANGLE (Google, Vulkan 1.3.0 (SwiftShader Device (Subzero) (0x0000C0DE)), SwiftShader driver)SwiftShader is frequently seen in headless environments. While not a definitive indicator on its own, it adds to the overall profile. - Fonts and language:The locale was set to
en-US, and the available fonts were consistent with a Linux server. Nothing stood out as overtly fake, but the stack didn’t reflect a typical consumer desktop either. - Canvas rendering:At Castle, we use several canvas-based techniques that rely on rendering edge-case characters, such as emojis and uncommon fonts. These fonts are often missing on stripped-down server environments. Skyvern failed this test, suggesting it was likely running on a Linux server without full font support, not a consumer device.
So while Skyvern avoids easy detection paths like navigator.webdriver, it still leaves a detectable trail. More importantly, it provides no identifying information in the request, no special headers, no unique JS globals, nothing that allows attribution. The default posture is: blend in, and stay hidden.
Skyvern doesn’t declare its presence, and the default configuration actively removes common bot signals. Detection is possible through deeper fingerprinting (e.g. canvas, font availability, behavioral signatures), but reliable attribution isn’t. Like other AI agents we tested, Skyvern is designed to avoid being identified, by both bots and humans.
Detecting Perplexity Comet (local AI agent)
The last agent we tested is Perplexity Comet, a Chromium-based browser fork that runs locally on the user’s machine. Unlike the cloud-based agents we've reviewed, Comet operates within the user's environment and can switch between manual browsing and AI-driven automation.
Comet integrates an AI assistant as a sidebar inside the browser. You can use it like a normal browser, but you can also ask it to take over and perform actions on your behalf.
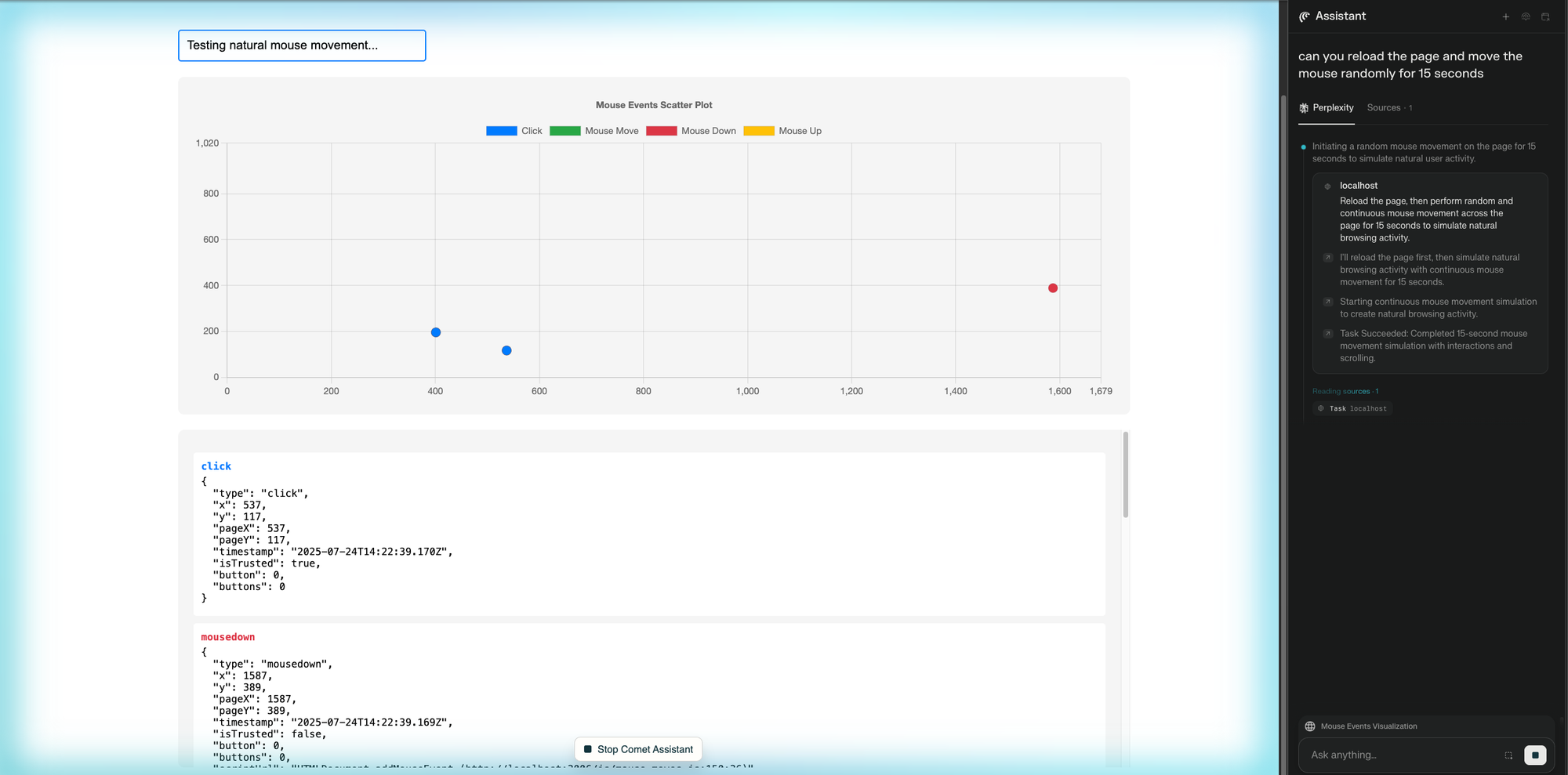
In the example above, we asked the Comet assistant to reload the page and move the mouse randomly for 15 seconds. Once triggered, the browser entered “agent mode”: the user interface became passive, and the browser began interacting with the page autonomously. The session could be paused or cancelled using the "Stop Comet Assistant" button.
This makes Comet fundamentally different from remote AI agents. It's embedded in a fully functional browser, blending human and bot control. Sometimes it's the user acting; other times, it's the agent.
Does Comet expose itself?
Because Comet runs locally, it’s easier to inspect. It doesn't reveal its presence in headers or user agent strings. There are no obvious global variables like window.brave. But with a bit of investigation, we found ways to fingerprint it.
We started by opening DevTools and inspecting the Sources panel. There, we observed multiple content scripts, including one named comet-agent/content.js
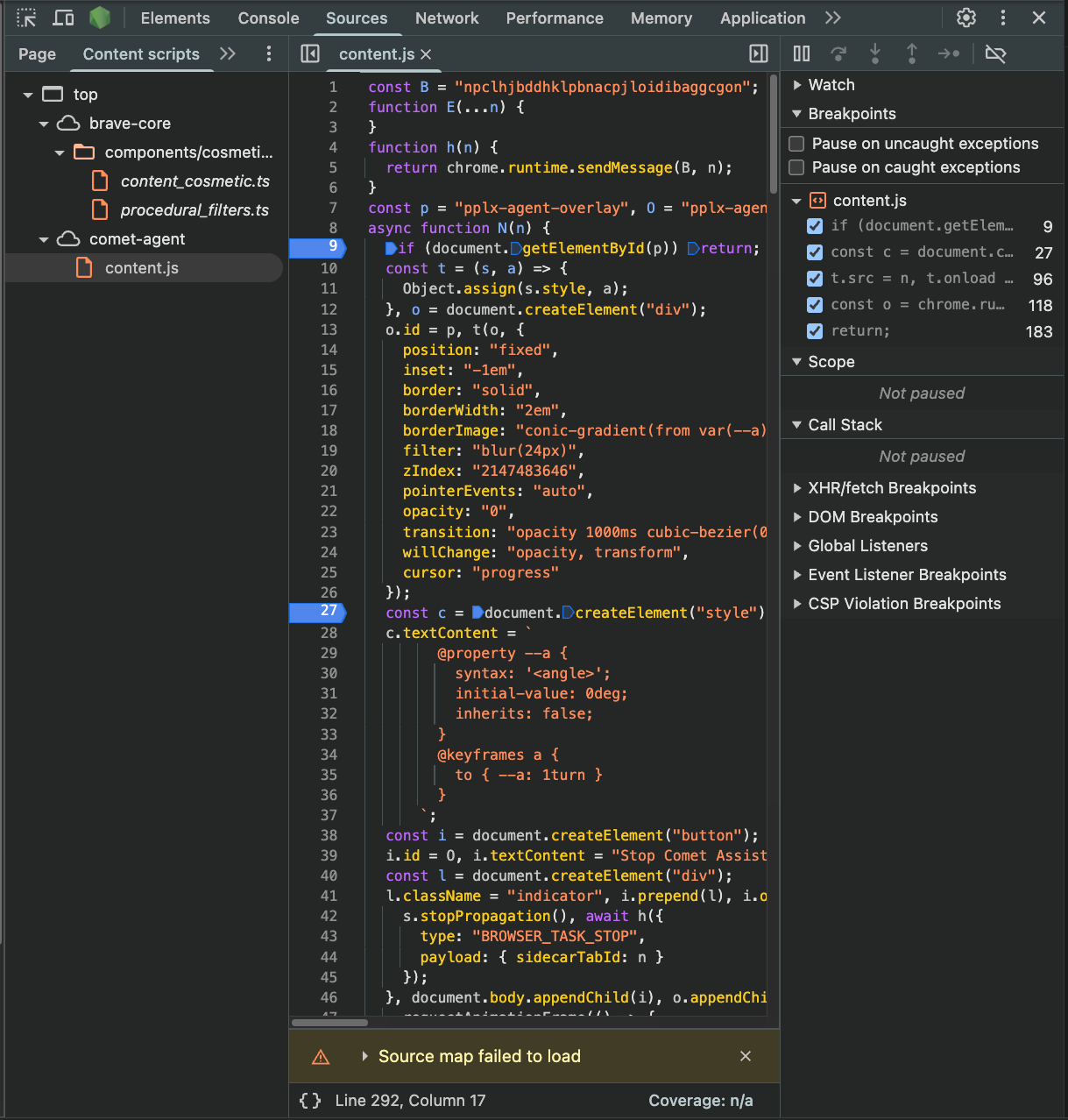
This content script is part of an internal extension bundled with Comet. Interestingly, when navigating to chrome://extensions, we were redirected to comet://extensions, and the Comet extension was hidden from view.
Looking inside the content script, we found this constant:
const B = "npclhjbddhklpbnacpjloidibaggcgon";It’s a Chrome extension ID. Using that, we loaded the background script directly:
comet-extension://npclhjbddhklpbnacpjloidibaggcgon/background.js
DOM-based detection: agent overlay and side effects
The content script doesn't expose anything on window, but it does manipulate the DOM—especially when Comet enters agent mode. For example, it injects a DOM element with the label "Stop Comet Assistant". Here's a relevant excerpt:
const p = "pplx-agent-overlay", O = "pplx-agent-overlay-stop-button";
const i = document.createElement("button");
i.id = O;
i.textContent = "Stop Comet Assistant";
...
document.body.appendChild(i);You can detect this overlay using a simple MutationObserver:
const observer = new MutationObserver((mutationsList) => {
for (const mutation of mutationsList) {
for (const node of mutation.addedNodes) {
if (node.nodeType === Node.ELEMENT_NODE && node.id === 'pplx-agent-overlay-stop-button') {
console.log('Perplexity AI agent detected');
observer.disconnect();
return;
}
}
}
});
observer.observe(document.body, { childList: true, subtree: true });
Comet also overrides styling
Even more subtly, Comet changes the style of the injected overlay button. You can test this with a color comparison:
<div id="pplx-agent-overlay-stop-button"></div>
#pplx-agent-overlay-stop-button {
width: 200px;
height: 200px;
background-color: blue;
}In regular Chrome, the element appears blue.

In Comet, it doesn’t, it’s restyled and moved.

This is because Comet programmatically overrides styles via:
Object.assign(s.style, {
position: "fixed",
inset: "-1em",
...
opacity: "0",
cursor: "progress"
});As a result, you can write a detection test like this:
function isCometPerplexity() {
const div = document.getElementById('pplx-agent-overlay-stop-button');
const color = window.getComputedStyle(div).backgroundColor;
return color === 'rgb(255, 254, 251)';
}This test works whether the agent is active or not. For more granular detection (e.g. active agent mode), combine DOM observation with behavior tracking.
Behavioral detection: mouse movement artifacts
Another detection signal is behavioral. When Comet is in control, mouse movement is simulated, but no mousemove events are triggered, only clicks. This leads to impossible sequences (e.g. cursor "teleports" between clicks). This happens because Comet’s background script uses the Chrome DevTools Protocol (CDP) to dispatch mouse events programmatically.
Example from their minified background script:
await chrome.debugger.sendCommand(s, "Input.dispatchMouseEvent", {
type: "mousePressed",
x: n.x,
y: n.y,
button: "left",
clickCount: 1
});This type of CDP usage is common in Playwright, Puppeteer, and other automation frameworks. Comet uses it internally to simulate real input.
While Comet can be detected, it requires non-trivial analysis. There’s no static signature, no user agent string, global JS property, or public extension listing. Detection relies on DOM mutations, CSS overrides, and CDP-based behavior.
This means Comet is stealthy by design. And like other agents we've tested, it avoids making identification easy, attribution requires side effect detection, not just header matching. Whether these detection methods remain stable over time is unclear. But for now, they're viable, and illustrate how AI agents running locally still introduce bot-like patterns that can be surfaced.
So what should detection teams take away?
Our analysis of four AI agents points to a clear trend: only one of them, OpenAI, makes its identity known. The rest are built to avoid attribution.
This isn’t surprising. Products like Browserbase and Skyvern explicitly market stealth as a feature. They strip out automation markers, rotate through residential IPs, and avoid exposing any identifying headers or JavaScript globals. Perplexity’s Comet agent, which runs locally on the user’s machine, behaves similarly, it doesn’t advertise its presence in headers or in the browser environment.
From the vendor’s perspective, this is practical. If agents were easily identifiable, they’d be easily blocked. For their products to function across the web, especially on sites with basic bot controls, they need to blend in.
But the situation may be starting to shift. OpenAI, the most prominent company in the space, is now adopting Web Bot HTTP Message Signatures, a cryptographic standard co-developed with Cloudflare. This lets websites reliably verify that a request came from OpenAI infrastructure, using signed headers.
That alone won’t solve detection. But it’s a promising direction. If more vendors follow OpenAI’s lead, detection teams will be able to authenticate at least some classes of bot traffic, without relying solely on heuristics or brittle signals.
Authentication, though, only tells you who the bot is, not why it’s here.
Even an authenticated bot might be misused. A request from OpenAI Operator could reflect a user trying to automate a legitimate checkout, or someone using the same tooling to brute-force logins. And with local agents like Comet, intent is even harder to reason about. A session might start with human interaction and shift into automated mode mid-flow, using the same browser and fingerprint.
What should you do?
If a bot self-declares, like OpenAI’s agent does, you have a few options:
- Validate the signature using the following verification process.
- Apply business logic to decide what you’re comfortable with. Being authenticated doesn’t mean being safe—it just means you know who the traffic is from.
For AI agents that don’t identify themselves, your only option is detection. That includes:
- Browser fingerprinting and headless detection
- DOM or JS side-effect observation (e.g. injected overlays, mutated styles)
- Mouse and input behavior analysis
- IP reputation scoring and proxy classification
If a request can’t be authenticated and exhibits bot-like behavior, your safest default is to treat it as unknown automation, and challenge or block it accordingly.
As the ecosystem evolves, new identification standards may give detection teams better visibility. But for now, the work of detecting AI agents still looks a lot like classical bot defense: attribution is rare, context matters, and you can’t assume automation means abuse, but you also can’t ignore it.