

Every month, we publish a list of fraudulent email domains observed across the websites and mobile apps we protect. See the July 2025 list for a recent example. These domains are tied to fake account creation and other abuse patterns, including:
- Disposable email services
- Custom throwaway domains registered explicitly for fraud
- Legitimate free providers with limited anti-abuse protections
Because we defend real-world properties at scale, we don’t just see popular disposable domains; we also see bespoke infrastructure attackers set up for specific campaigns. These custom domains rarely show up on public blocklists and often disappear after a short burst of activity.
In this post, we explore a graph-based technique to cluster fraudulent domains that appear related. The goal isn’t detection per se, but discovery: surfacing groups of domains that share similar traits and are likely controlled by the same operator. This is useful for understanding attacker infrastructure and identifying abuse patterns that would be missed when looking at domains in isolation.
We focus on practical signals you can extract from public sources:
- Features derived from a domain’s HTML content
- Fingerprints of the server’s HTTP response
- DNS records and related metadata
This is not a productized model, and the value isn’t in a specific implementation. Our aim is to share a method, using simple graph construction, that can help fraud teams connect the dots across seemingly unrelated domains.
We use an intentionally low-tech approach: no ML, no embeddings. Just nodes and edges, where each edge represents a shared attribute (like an IP address or a matching HTML fingerprint). While you could achieve similar results with clustering algorithms like DBSCAN, graph-based methods are well-suited to fraud analysis, where you often care more about relationships between entities than global structure.
Data collection
For this study, we used the fraudulent email domains identified in Castle’s June and May 2025 reports. After deduplication, the dataset included 332 unique domains observed in connection with fake or malicious signups.
We then built a script to collect structural and network-level signals for each domain. While the implementation is straightforward, just HTTP requests and DNS lookups, we applied consistent parsing logic and normalized missing values as 'NA'.
Website and server response signals
The first category of signals reflects the structure and behavior of the web server associated with each domain. For example, for blueink.top, we inspect the site hosted at https://blueink.top/.
We perform an HTTP GET request and capture both the raw HTML and the server response headers. From these, we extract several derived features.
Example HTML-derived fields:
"title": "Mailu-Admin | CT Mail",
"first_h1_text": "Sign in",
"html_hash": "80f19cfce65e864d806c6473a3580f6af89b2795cd269620f36c803383666393",
"h1_count": 1,
"h2_count": 0,
"link_count": 34,
"paragraph_count": 4,
"input_count": 5,
"submit_count": 2
Example server response fields:
"header_keys_hash": "db301bc56667ecc6ad08a4f3d298ba4a39fe456f5794052abc2a5ab6a312e88b",
"header_values_hash": "cb825b625272cbd5fb01b480c85a80d513c2eb4f851a9b58435a0e2d297cce28",
"server": "cloudflare",
"content_type": "text/html",
"content_length": "NA",
"cache_control": "NA",
"last_modified": "Wed, 08 Jan 2025 05:14:07 GMT",
"connection": "keep-alive",
"transfer_encoding": "chunked",
"content_encoding": "gzip",
"pragma": "NA",
"x_powered_by": "NA",
To ensure consistent comparisons in the next part, we excluded unstable headers (e.g. timestamps) from the header_values_hash calculation:
variable_headers = {
'Date', 'Last-Modified', 'Expires', 'CF-RAY', 'ETag', 'Set-Cookie',
'server-timing', 'report-to', 'alt-svc'
}
DNS signals
We also collected DNS-level information using the Python dns library, including A, MX, TXT, and DMARC records:
"ip_address": "178.162.170.166",
"ptr_record": "NA",
"a_record": "178.162.170.166",
"mx_records": "mail.guerrillamail.com.",
"txt_records": "\\"v=spf1 mx a ip4:178.162.170.166 -all\\"",
"spf_record": "\\"v=spf1 mx a ip4:178.162.170.166 -all\\"",
"dmarc_record": "\\"v=DMARC1; p=reject; sp=reject; rf=afrf; pct=100; ri=86400\\""
For each domain, the script aggregates a full set of features. Here’s a sample output for emailclub.net:
{
"email_domain": "emailclub.net",
"title": "Mailu-Admin | CT Mail",
"first_h1_text": "Sign in",
"html_hash": "80f19cfce65e864d806c6473a3580f6af89b2795cd269620f36c803383666393",
"h1_count": 1,
"h2_count": 0,
"link_count": 34,
"paragraph_count": 4,
"input_count": 5,
"submit_count": 2,
"header_keys_hash": "152cf184ffae5511557b5efc03f8fa7603e4f93beeb8c471ce62cc38dd577e74",
"header_values_hash": "6ee681b249005d4c0231628e99c7ff844566908648f84831127b60259df427b6",
"server": "nginx",
"content_type": "text/html; charset=utf-8",
"content_length": "NA",
"cache_control": "NA",
"last_modified": "NA",
"connection": "NA",
"transfer_encoding": "NA",
"content_encoding": "gzip",
"pragma": "NA",
"x_powered_by": "NA",
"ip_address": "80.66.79.245",
"ptr_record": "server.dedic.",
"a_record": "80.66.79.245",
"mx_records": "mail.emailclub.net.",
"txt_records": "\\"v=spf1 mx a:emailclub.net ~all\\"",
"spf_record": "\\"v=spf1 mx a:emailclub.net ~all\\"",
"dmarc_record": "\\"v=DMARC1; p=reject; rua=mailto:admin@mailgod.xyz; ruf=mailto:admin@mailgod.xyz; adkim=s; aspf=s\\""
}
Preprocessing and graph construction
Before we can cluster domains, we need to define what it means for two email domains to be “linked.” We’re not using machine learning to classify domains as malicious or not, the goal here is exploratory. We want to surface groups of domains that appear related based on shared infrastructure or presentation.
Instead of classical clustering algorithms like DBSCAN or K-Means, we use a graph-based approach. Each domain becomes a node, and we add edges between domains that share meaningful features (e.g. same IP, similar HTML structure). This structure gives us interpretable clusters and lets us flexibly define what constitutes a “link.”
Fingerprinting and normalization
We start with a Pandas dataframe df containing our scraped data:
df = pd.read_json('./data/results.json')
We do some basic normalization, such as extracting the first MX record when multiple are present:
df['first_mx_record'] = df['mx_records'].apply(
lambda x: x.split(',')[0].strip() if isinstance(x, str) and x else None
)
Then we generate lightweight fingerprints based on HTML structure and HTTP headers. These aren’t meant to be globally unique—just useful for clustering.
def build_html_fingerprint(row):
if row['h1_count'] == 'NA' or row['submit_count'] == 'NA' or (row['title'] == 'NA' and row['first_h1_text'] == 'NA'):
return 'NA'
raw_string = (
str(row['h1_count']) +
str(row['h2_count']) +
str(row['link_count']) +
str(row['paragraph_count']) +
str(row['input_count']) +
str(row['submit_count']) +
str(row['first_h1_text'] is not None)
)
return hashlib.sha256(raw_string.encode('utf-8')).hexdigest()[0:8]
The HTML fingerprint is based on structural features, so minor content changes (e.g. a different H1 text) shouldn’t affect it. We also define a hybrid fingerprint combining HTML and server signals:
def build_hybrid_fingerprint(row):
if row['html_fingerprint'] == 'NA' or row['header_keys_hash'] == 'NA':
return 'NA'
return row['html_fingerprint'] + row['header_keys_hash'] + row['server'] + row['x_powered_by']
Graph building
Once each domain has enriched attributes, we construct a graph using NetworkX. Each edge type corresponds to a different signal—shared IP, shared MX, similar headers, etc. We first build index maps to find all domains with the same fingerprint:
ip_index = defaultdict(set)
mx_index = defaultdict(set)
headers_hash_index = defaultdict(set)
html_fingerprint_index = defaultdict(set)
hybrid_fingerprint_index = defaultdict(set)
for _, row in df.iterrows():
domain = row['email_domain']
ip = row['ip_address']
if isinstance(ip, str) and ip != 'NA':
ip_index[ip].add(domain)
mx = row['first_mx_record']
if isinstance(mx, str) and mx != 'NA':
mx_index[mx].add(domain)
h = row['header_keys_hash']
if isinstance(h, str) and h != 'NA':
headers_hash_index[h].add(domain)
html_fp = row['html_fingerprint']
if isinstance(html_fp, str) and html_fp != 'NA':
html_fingerprint_index[html_fp].add(domain)
hf = row['hybrid_fingerprint']
if isinstance(hf, str) and hf != 'NA':
hybrid_fingerprint_index[hf].add(domain)
Then we define a helper to create edges between domains that share a value:
def add_edges(G, index_dict, edge_type):
for shared_value, domains in index_dict.items():
if len(domains) < 2:
continue # no link if value is not shared
for d1, d2 in combinations(domains, 2):
if G.has_edge(d1, d2):
G[d1][d2]['link_types'].add(edge_type)
else:
G.add_edge(d1, d2, link_types={edge_type})
And finally, we build the graph. In the example below, we add an edge between two nodes only if both email domains have the same IP address.
import networkx as nx
G = nx.Graph()
# Add nodes
for domain in df['email_domain']:
G.add_node(domain)
add_edges(G, ip_index, 'shared_ip')
Clustering email domains with NetworkX
Once the graph is built, clustering is simple: we use networkx.connected_components() to identify groups of email domains that are transitively connected through shared signals like IPs or fingerprints.
clusters = list(nx.connected_components(G))
This gives us sets of domains where every node is reachable from every other node via some sequence of shared features.
To explore the clusters, we define a utility function that prints clusters above a minimum size, along with the types of links (edges) that explain their connections:
def print_clusters_with_links(graph, min_size=2):
clusters = list(nx.connected_components(graph)) # for undirected graphs
for idx, component in enumerate(clusters):
if len(component) >= min_size:
print(f"\\nCluster {idx + 1} (size={len(component)}):")
print("Domains:", sorted(component))
# Collect all link types in this cluster
link_types = set()
# Iterate over all pairs in component and extract edge reasons
subgraph = graph.subgraph(component)
for u, v, data in subgraph.edges(data=True):
link_types.update(data.get('link_types', []))
print("Reasons (edge types):", sorted(link_types))
print_clusters_with_links(G, min_size=5)
Running this with a minimum size of 5 shows clusters of related domains, grouped by shared infrastructure:
Cluster 21 (size=14):
Domains: ['01dasrock.shop', 'fivemx.shop', 'hfdafkfcdbu.shop', 'hotmaiill.cloud', 'ignity.space', 'lorranboss.shop', 'tksobsghost.cloud', 'unbanneds.shop', 'vierasigma.shop', 'vkfivem.shop', 'voltaex.fun', 'xitados.cloud', 'xitarearte.shop', 'xiters.cloud']
Reasons (edge types): ['shared_ip']
Cluster 23 (size=8):
Domains: ['bokomail.fun', 'bokomail.live', 'bokomail.shop', 'bokomail.today', 'hufmail.online', 'jojomail.online', 'jojomail.store', 'jojomail.today']
Reasons (edge types): ['shared_ip']
...
Cluster 73 (size=5):
Domains: ['gemil.com', 'htmail.com', 'icloid.com', 'icolud.com', 'igmail.com']
Reasons (edge types): ['shared_ip']
Cluster 100 (size=22):
Domains: ['aceomail.com', 'atorymail.com', 'bolivianomail.com', 'chiefmail.kr.ua', 'chromomail.com', 'corporate.vinnica.ua', 'deformamail.ru', 'demainmail.com', 'difficilemail.com', 'eblanomail.com', 'estabamail.com', 'firstmailler.com', 'hepatomolml.ru', 'privateemail.uz.ua', 'puedemail.com', 'quieresmail.com', 'regardermail.com', 'ronaldofmail.com', 'streetwormail.com', 'tubermail.com', 'utiliseremail.com', 'wildbmail.com']
Reasons (edge types): ['shared_ip']
Expanding the linking criteria
We can increase cluster coverage by including more signals. For example, domains may be linked if they share:
- the same IP address
- the same MX record
- the same HTML fingerprint
- similar HTTP headers
- a combined “hybrid” fingerprint
add_edges(G, ip_index, 'shared_ip')
add_edges(G, mx_index, 'shared_mx')
add_edges(G, headers_hash_index, 'shared_headers_hash')
add_edges(G, hybrid_fingerprint_index, 'shared_hybrid_fingerprint')
add_edges(G, html_fingerprint_index, 'shared_html_fingerprint')
This broader approach naturally increases cluster size, but it also increases the risk of noise and false positives. For instance, domains running the same open source webmail or behind the same CDN might be grouped together without any malicious connection. That’s what happens in this example when we allow too many types of connections. We see that it’s grouping unrelated domains together, cf example below:
Cluster 11 (size=53):
Domains: ['123.com', '123gmail.com', '1gmail.com', '52you.vip', 'agmail.com', 'autlook.com', 'azuretechtalk.net', 'babupro.xyz', 'bangban.uk', 'boxfi.uk', 'byom.de', 'deoxidizer.org', 'designmask.xyz', 'doxbin.bar', 'dreamclarify.org', 'exdonuts.com', 'fivegen.fr', 'fivemready.org', 'forexzig.com', 'fxzig.com', 'gemil.com', 'gmain.com', 'gmaip.com', 'haren.uk', 'hotmial.com', 'htmail.com', 'icloid.com', 'iclound.com', 'icolud.com', 'igmail.com', 'jmail.com', 'logsmarter.net', 'lolihentai.live', 'miruna.lol', 'mmoko.com', 'momoxontop.com', 'outllok.com', 'outloo.com', 'perc30s.org', 'polkaroad.net', 'rapeme.best', 'schizololi.help', 'sexintens.cam', 'sextoys.forum', 'sofaion.com', 'svk.jp', 'sweetdoggo.xyz', 'thetechnext.net', 'tuamaeaquelaursa.com', 'vetements.help', 'via.tokyo.jp', 'virgintommy.in', 'zangaofc.xyz']
Reasons (edge types): ['shared_headers_hash', 'shared_html_fingerprint', 'shared_hybrid_fingerprint', 'shared_ip', 'shared_mx']
Targeted clustering strategy
You can also narrow the linking criteria to improve precision. For example, using just three edge types:
add_edges(G, ip_index, 'shared_ip')
add_edges(G, mx_index, 'shared_mx')
add_edges(G, hybrid_fingerprint_index, 'shared_hybrid_fingerprint')
This yields cleaner, high-confidence groupings, such as:
Cluster 17 (size=23):
Domains: ['azuretechtalk.net', 'babupro.xyz', 'byom.de', 'deoxidizer.org', 'designmask.xyz', 'doxbin.bar', 'fivemready.org', 'forexzig.com', 'fxzig.com', 'logsmarter.net', 'lolihentai.live', 'miruna.lol', 'mmoko.com', 'perc30s.org', 'polkaroad.net', 'rapeme.best', 'schizololi.help', 'sexintens.cam', 'sextoys.forum', 'thetechnext.net', 'tuamaeaquelaursa.com', 'vetements.help', 'virgintommy.in']
Reasons (edge types): ['shared_hybrid_fingerprint', 'shared_ip', 'shared_mx']
Cluster 19 (size=10):
Domains: ['enotj.com', 'fxavaj.com', 'hthlm.com', 'nbmbb.com', 'nesopf.com', 'nespf.com', 'nespj.com', 'poplk.com', 'xfavaj.com', 'ytnhy.com']
Reasons (edge types): ['shared_hybrid_fingerprint', 'shared_mx']
Cluster 20 (size=15):
Domains: ['01dasrock.shop', 'fivemx.shop', 'hfdafkfcdbu.shop', 'hotmaiill.cloud', 'ignity.space', 'lorranboss.shop', 'protcapplication.shop', 'tksobsghost.cloud', 'unbanneds.shop', 'vierasigma.shop', 'vkfivem.shop', 'voltaex.fun', 'xitados.cloud', 'xitarearte.shop', 'xiters.cloud']
Reasons (edge types): ['shared_hybrid_fingerprint', 'shared_ip', 'shared_mx']
Cluster 23 (size=19):
Domains: ['2mails1box.com', '300bucks.net', 'blueink.top', 'desumail.com', 'e-mail.lol', 'emailclub.net', 'energymail.org', 'homingpigeon.org', 'kakdela.net', 'letters.monster', 'lostspaceship.net', 'message.rest', 'myhyperspace.org', 'postalbro.com', 'rocketpost.org', 'shroudedhills.com', 'whyusoserious.org', 'wirelicker.com', 'writemeplz.net']
Reasons (edge types): ['shared_hybrid_fingerprint', 'shared_ip']
Cluster 87 (size=22):
Domains: ['aceomail.com', 'atorymail.com', 'bolivianomail.com', 'chiefmail.kr.ua', 'chromomail.com', 'corporate.vinnica.ua', 'deformamail.ru', 'demainmail.com', 'difficilemail.com', 'eblanomail.com', 'estabamail.com', 'firstmailler.com', 'hepatomolml.ru', 'privateemail.uz.ua', 'puedemail.com', 'quieresmail.com', 'regardermail.com', 'ronaldofmail.com', 'streetwormail.com', 'tubermail.com', 'utiliseremail.com', 'wildbmail.com']
Reasons (edge types): ['shared_ip']
This flexibility is key. You can dial your clustering up or down based on the tolerance for false positives, and the goal of your analysis.
Analyzing clusters
We now take a closer look at the clusters generated using shared_ip, shared_mx, and shared_hybrid_fingerprint. These clusters are built to surface high-confidence relationships between domains, even if some individual signals differ.
Cluster 23: likely operated mail server
Cluster 23 contains 19 domains, all of which redirect to a login page hosted under the /sso/login path. For instance:
- Visiting 300bucks.net redirects to:
https://300bucks.net/sso/login?url=/webmail/?homepage - The same redirection is seen for blueink.top and the other email domains of the cluster:
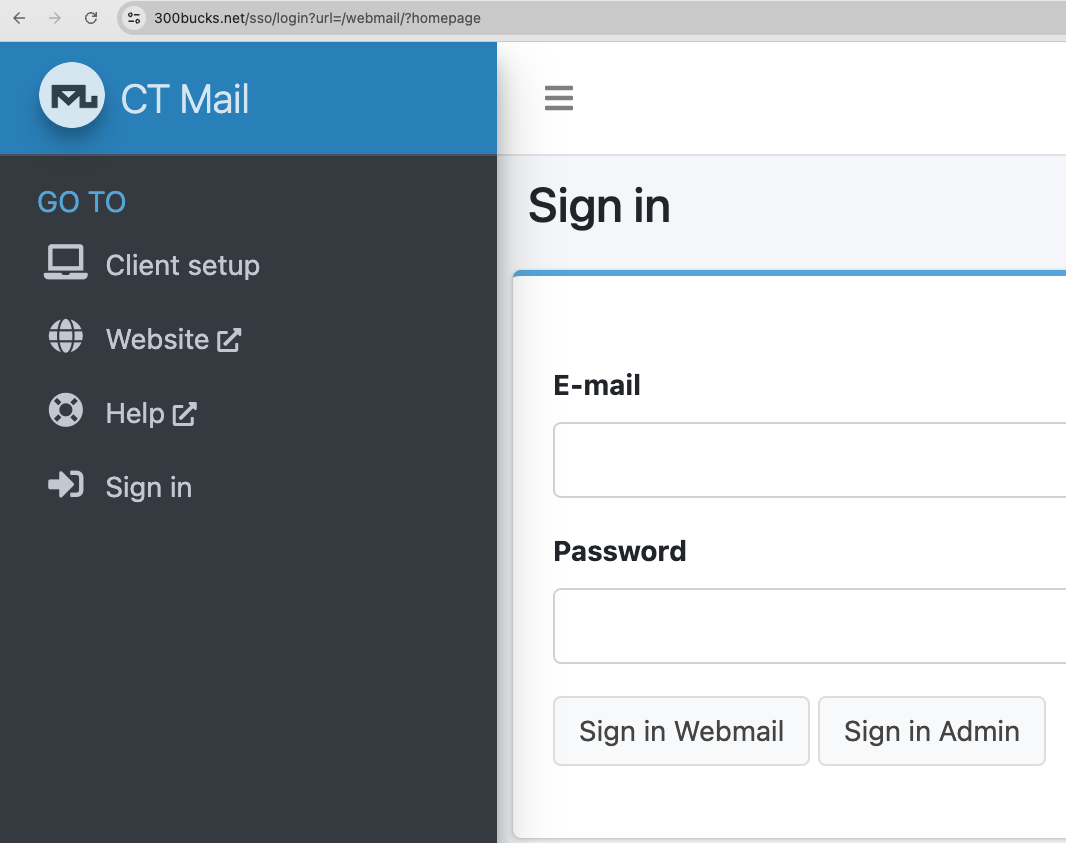
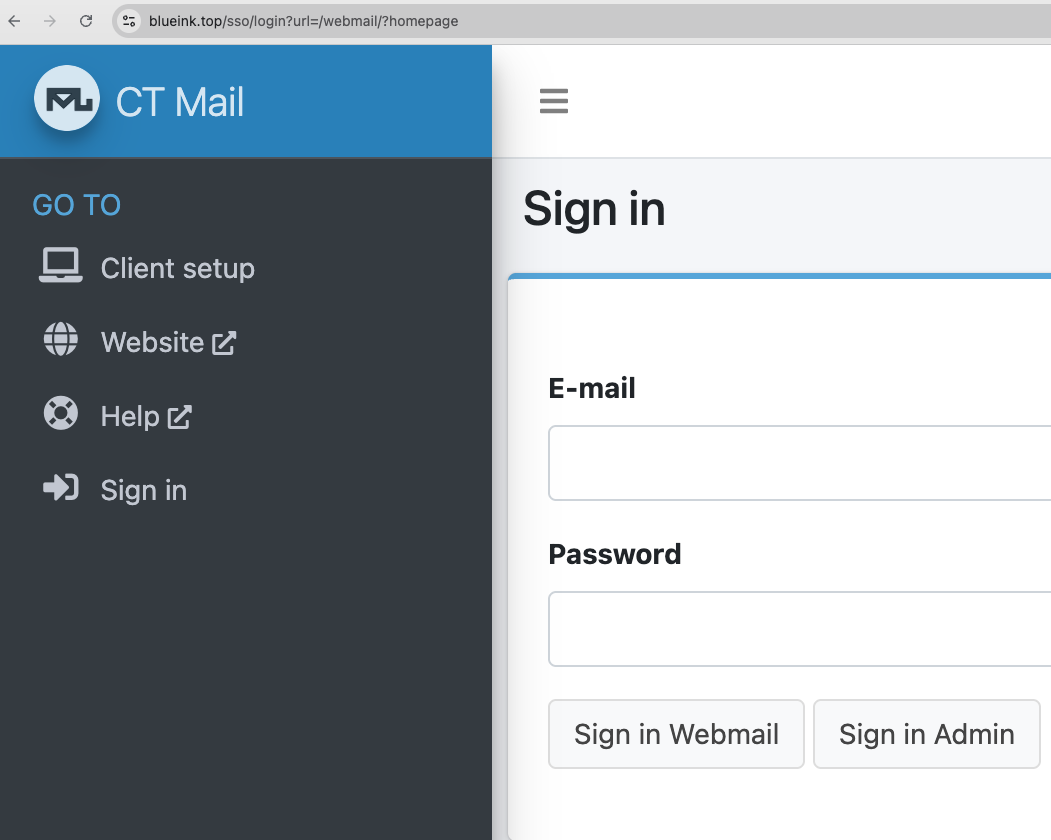
Under the hood, these domains appear to use Mailu, an open source mail server stack. The HTML and server response fingerprints also suggest Flask served behind Nginx:
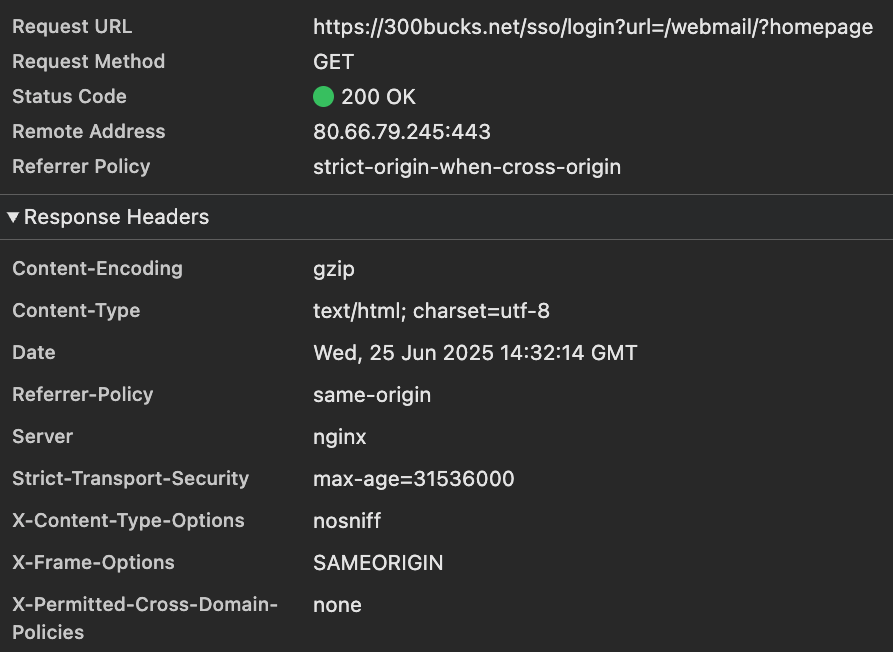
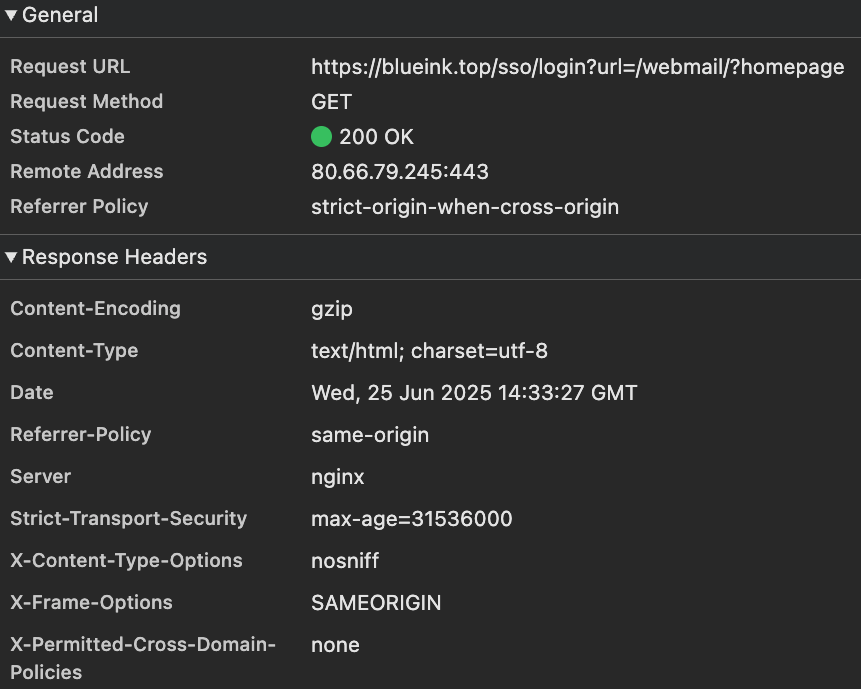
All domains in this cluster share IPs and a common hybrid fingerprint. We also observed them targeting the same customer, a business offering gift cards and prepaid products. Taken together, this points strongly to a single operator using a self-hosted mail server for fraud.
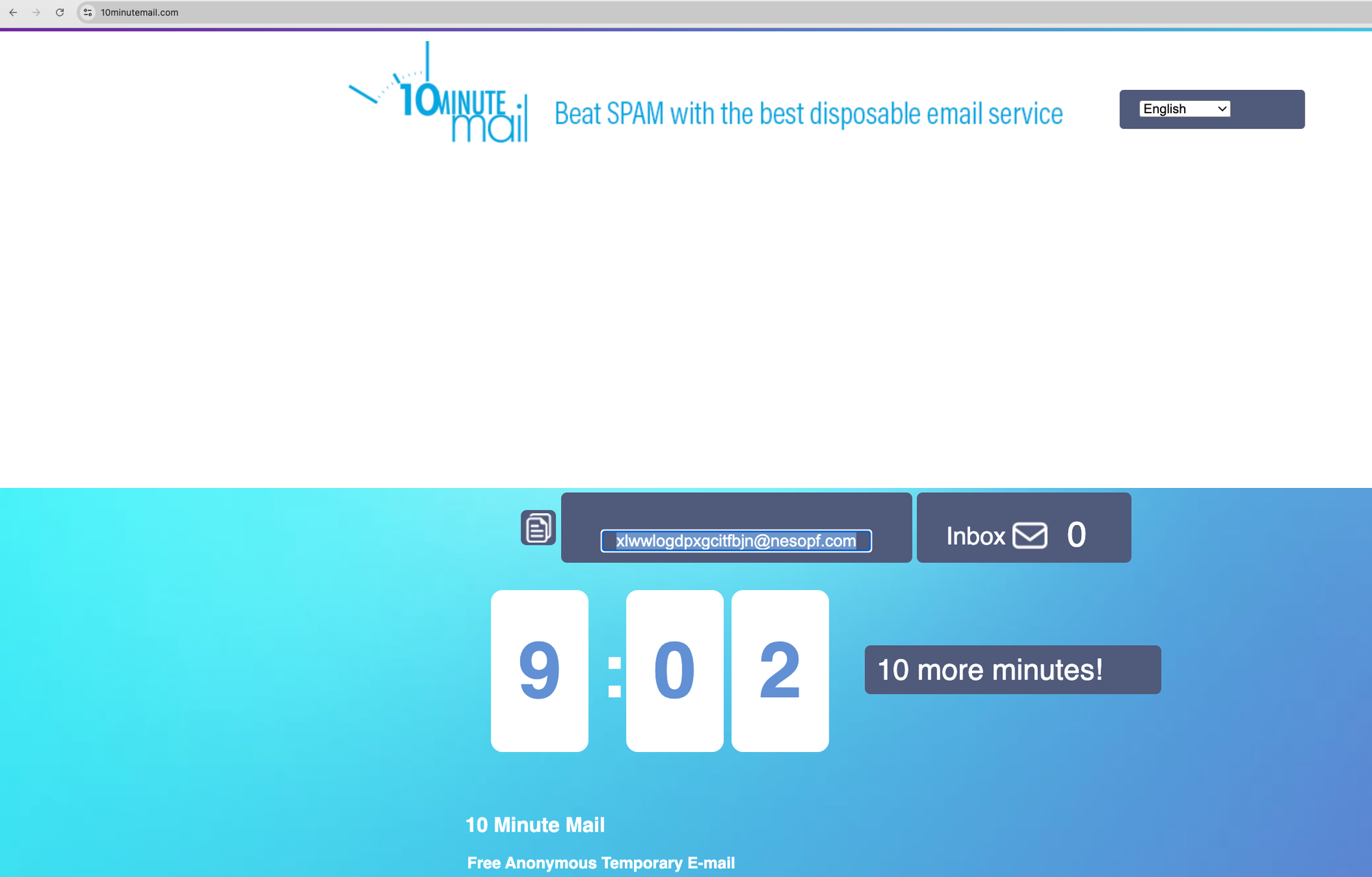
Cluster 19: linked to disposable mail
This cluster contains domains like:
enotj.comfxavaj.comhthlm.com
Each of them returns the same frontend used by 10MinuteMail, a disposable email provider:
These domains share MX records and hybrid fingerprints, indicating backend reuse across sibling brands of the same provider.
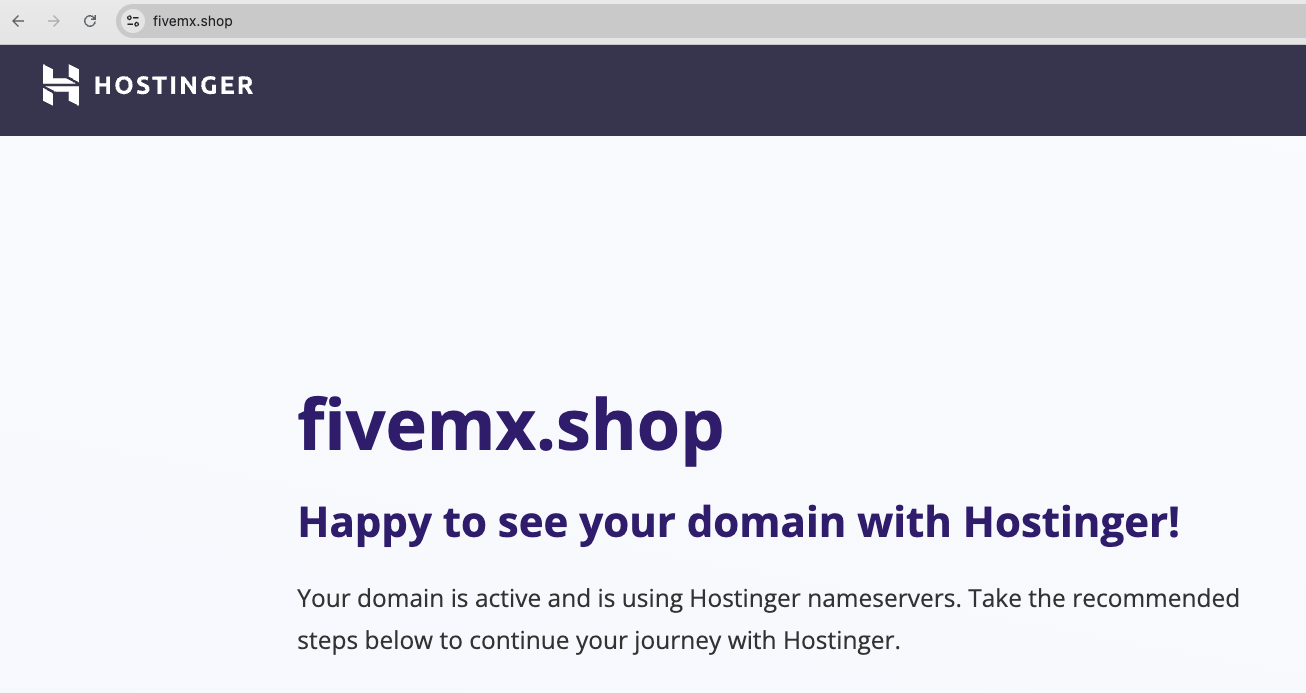
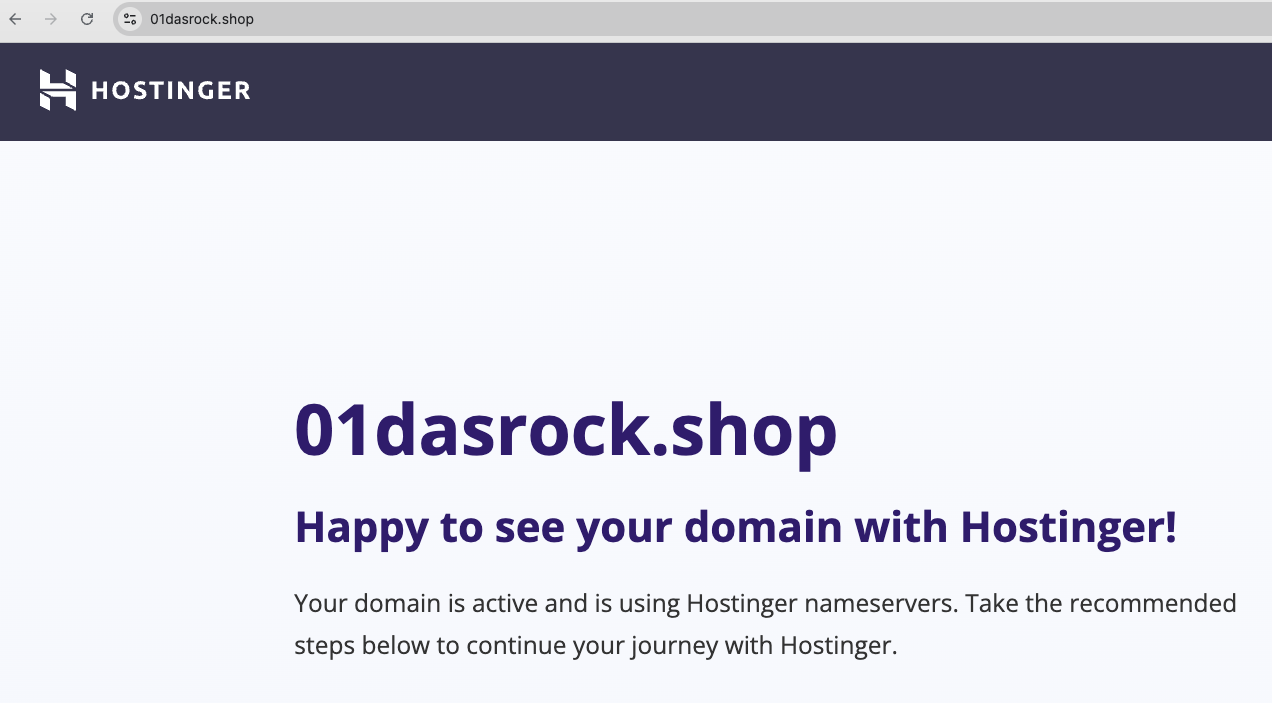
Cluster 20: abuse on a gaming platform
Domains in this group include:
01dasrock.shopfivemx.shophfdafkfcdbu.shop
All are hosted via Hostinger, as confirmed by IPs and headers:
Looking at customer traffic, we found all domains in this cluster targeting the same video game platform, and only that platform. Combined with shared IPs, MX records, and fingerprints, this suggests they’re part of a coordinated campaign by a single fraudster.
The limits of this approach, and what to try next
The method we’ve described, clustering domains using graph-based relationships, is intentionally simple, flexible, and interpretable. But applying it effectively requires careful attention to both limitations and extensions.
Limitations and tradeoffs
The signals we used (HTML fingerprints, MX records, server headers, IPs) are valuable but imperfect. False positives can arise when:
- Multiple domains use the same open source webmail UI or shared hosting.
- DNS records point to the same CDN IP (e.g. Cloudflare), creating misleading links.
- Email providers operate infrastructure that overlaps across brands or services.
To reduce noise, you can increase the strictness of your edge criteria. For example, require that two domains share both an IP and a fingerprint, not just one. The tighter the linking rule, the fewer unrelated domains you'll cluster together. But you'll also risk missing weaker (yet real) connections.
It’s also important to recognize scope: we applied this technique only to domains already known to be malicious. The goal was exploratory, understanding attacker infrastructure, not production detection.
From clustering to detection
That said, this method can evolve into a lightweight detection system. Here’s how:
- Use historical data to build a graph of known good and bad domains.
- Label clusters based on ground truth.
- When a new domain appears, extract its fingerprints and connect it to the graph.
- If it joins a known bad cluster, flag it for review or apply soft friction.
This can serve as a weak signal in a broader decision engine. And it doesn’t have to be graph-based: you could also use unsupervised clustering (e.g. DBSCAN) or train a supervised model (e.g. CatBoost, Random Forest) on extracted features.
Choosing the right granularity
Clustering at the domain level only makes sense when the domain is clearly tied to abuse. Many disposable domains fall into this category. But in other cases (e.g. Gmail), abuse coexists with legitimate traffic.
This mirrors broader fraud detection tradeoffs:
- ASN-level blocking is broad and risky.
- IP-level is narrower but can still cause false positives.
- Session-level or user-level granularity is most precise.
Email domains are no different. When abuse is concentrated on specific addresses within a domain, coarse domain-level blocks won't work. You’ll need to rely on signals at the address, session, or behavior level.
What’s next
We kept this demo deliberately simple. You could improve it by incorporating:
- WHOIS data and domain age
- TLS and certificate fingerprints
- Hosting provider or ASN metadata
- Behavioral data if available (e.g. signup patterns)
You can also extend the graph over time to identify infrastructure reuse or reemergence. Fraudsters often recycle setups, catching one cluster early could surface dozens of future domains with minimal effort.


