

I recently had an ant problem in my apartment.
At first, it looked simple. We saw ants coming through the window of one room. After looking around for a while, we found two small holes in the window frame and some window seals that were not perfectly tight.

It felt like the kind of problem where the fix is obvious: block the entry points, kill the ants already inside, clean the area, and move on. We did exactly that, and for a few days it looked like the problem had disappeared.
Then the ants came back somewhere completely different. This time they appeared on the opposite side of the apartment, far from any window or door, in a place that seemed isolated from the outside. There was no obvious path, no visible connection to the first room, and no clear explanation.
That is when it became clear that the first fix had only solved the part of the problem we could observe. The source was still hidden, and what we had patched was only one visible symptom.
Why the gel made the problem more visible
At that point, we tried something different: ant gel.
The idea is simple. You place a toxic gel where ants are active. The gel attracts them. They eat it, go back to the nest, and share it with the colony through trophallaxis, the process where ants exchange food with each other.

What I found interesting is that, for a short period of time, the gel makes the problem look worse.
You do not place the gel and immediately see fewer ants. You often see more of them because the trap attracts them on purpose. It creates activity where you would rather see none.
That feels counterintuitive when your goal is to get rid of ants from your apartment. The instinctive reaction is to spray them, kill the visible ones, and make the problem disappear from the floor, the wall, the kitchen, or wherever you are seeing them.
Spray gives you the short-term satisfaction of removing what is in front of you. Gel accepts temporary discomfort in exchange for a better chance of reaching the real source of the problem.
In our case, it also made the system more observable. By watching where the ants went after finding the gel, we discovered another entry point outside the apartment, near a wall. They were coming in through a small hole under a door, then moving under the baseboards before reappearing much further inside.

The place where they surfaced was just the point where their hidden path became visible again. It was easy to confuse that point with the source.
Visible abuse is often just the surface
This article is about ants only because they made a useful detection problem visible in a physical space. I am not comparing users, or even fraudsters, to ants. The analogy is about how we investigate a system when we only see part of the activity.
In fraud detection, it is easy to optimize for removing the visible symptom.
- You see a fake account, so you block it.
- You see a burst of signups from a suspicious IP, so you rate limit it.
- You see a disposable email domain, so you add it to a blocklist.
Sometimes that is the right thing to do. If the abuse is active and risky, you need to stop it. There is no virtue in letting attackers damage your platform just because you want more data.
But if every detection decision immediately turns into a hard block, you may only ever remove the activity you can already see.
You remove one account, one IP, one email domain, or one device fingerprint. The attacker adjusts, rotates, and comes back through another path. From the outside, it looks like a new problem, while it may simply be the same campaign showing up through a different visible entry point.
The hard part is not always detecting one malicious entity. Often, the harder and more useful question is what else that entity is connected to.
Start with a seed you trust
A useful way to approach this is to start from a high-confidence seed.
The seed does not have to be large. In fact, it is often better if it is small but very reliable.
For example:
- accounts created with disposable email services you have verified yourself
- accounts using temporary phone numbers
- emails generated through a known automation service
- devices already linked to confirmed abuse
- sessions tied to a known bot framework
- payment instruments, invite codes, or referral patterns already associated with fraud
The important point is confidence. If the initial seed is noisy, everything built from it will inherit that noise.
From there, you can start looking at relationships.

A fraud account is rarely just an account. It usually has links to other entities: session cookies, device fingerprints, IPs, proxies, email patterns, phone numbers, behavioral fingerprints, payment methods, invite relationships, and timing patterns.
Some of these links are strong, while others are weak.
A shared stable session cookie between two accounts is usually a stronger link than a shared IP address. A shared device fingerprint may be meaningful, depending on how it is built and how much collision risk it has. An IP plus similar hardware characteristics plus a narrow time window may be useful, but it is clearly weaker than a direct identifier.
This is where graph thinking becomes useful.
You can represent accounts and related entities as nodes. You can represent relationships between them as edges. Then you can look for groups of accounts that are strongly connected to known fraud seeds.
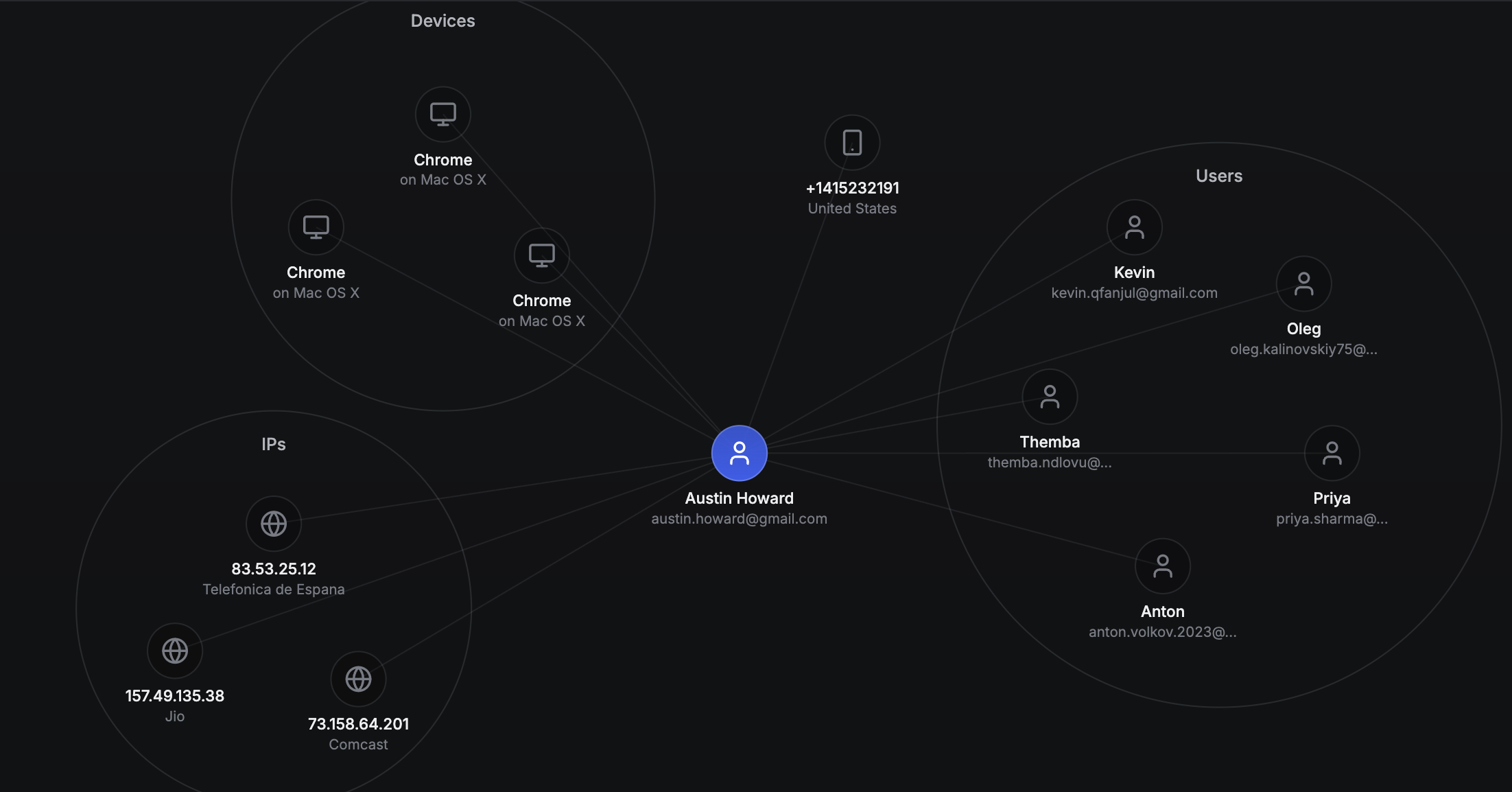
That graph should guide investigation rather than act as the final decision. It helps decide where to look next, which entities deserve more scrutiny, and which relationships need validation with additional signals.
Use the graph to investigate, not to convict
This is where many detection systems get risky.
It is tempting to say: this account is connected to a bad account, therefore this account is bad too. However, that logic is often wrong.
Legitimate users can share infrastructure with attackers. They can be behind the same carrier-grade NAT. They can use the same VPN provider. They can receive messages from compromised accounts. They can interact with fraudulent accounts in ways that do not make them part of the fraud scheme.
Even strong-looking connections can be misleading if you do not understand how they were created.
For example, a device fingerprint is not a magic identity. Depending on the attributes used, it may be very precise or very broad. A fingerprint built from coarse browser and hardware properties can group many unrelated users. An IP address can represent a household, an office, a mobile carrier, a proxy exit, or a data center. A behavioral pattern can describe automation, but it can also reflect a common user flow if it is too generic.
So the question is not simply whether an entity is linked to fraud. The better question is what kind of link exists, how reliable it is, and whether the rest of the behavior supports the same conclusion.
That is why propagation needs guardrails.
Useful guardrails include:
- requiring multiple independent links before escalating risk
- weighting edges differently depending on their precision
- limiting how far risk can propagate from the original seed
- reviewing very large clusters, because they often indicate a noisy edge
- ignoring or downgrading links through shared infrastructure such as common VPNs, mobile networks, or large offices
- checking whether trusted or long-lived accounts are being pulled into the cluster
- validating that newly discovered accounts behave similarly over time
- separating investigation labels from enforcement labels
This last point is important.
Tagging an account as worth investigating is different from blocking it. A graph can be excellent for discovery while still being too noisy for direct enforcement.
Why immediate blocking can make you blind
Another thing I found interesting with the gel is that it only works because it does not kill too fast.
If the poison acted immediately, it would solve the visible part of the problem, but the ants would never have enough time to bring it back to the nest. The delay is what makes the trap useful. It gives the system time to expose more of itself before the effect fully kicks in.
There is a similar tradeoff in fraud detection.
When you block an attacker too early and too clearly, you give them feedback. You tell them which account was caught, which request failed, which signal may have triggered the decision, and sometimes which part of their infrastructure is burned.
That does not mean you should avoid blocking. It means the response should match the risk.
For high-risk actions, blocking or strong verification may be necessary. If an account is about to withdraw money, abuse a promotion, spam users, or perform any action with direct impact, there is no reason to keep observing for the sake of collecting more data.
For lower-risk actions, it can be more useful to tag, observe, limit, or delay enforcement. A confirmed fake account that is still browsing harmless pages may reveal useful connections. It may reuse a device. It may log in from a related proxy. It may invite other accounts. It may attempt the same action sequence as the rest of the campaign. It may expose another email pattern, another phone provider, or another piece of automation infrastructure.
If you block it instantly, you stop the immediate activity, but you may also cut the thread that would have led you to the rest of the network.
This is the part that maps back to the gel trap. The delay is not inaction. It is part of the mechanism. The point is to let the signal travel far enough to reveal the structure behind the visible activity, while still controlling what damage can happen in the meantime.
That distinction matters. Observation has to be bounded and risk-managed. You do not let an account harm users, drain value, or abuse the platform just because it may reveal more signals later.
But between “allow everything” and “block immediately”, there is a useful middle ground:
- silently increase risk
- require verification only at sensitive moments
- restrict high-impact actions
- delay visible failure messages
- monitor linked entities
- add friction progressively
- use the account as an investigation seed
Done carefully, this reduces attacker feedback while improving visibility. The goal is not to let the attack continue. The goal is to avoid burning the one path that could reveal the rest of the campaign.
Make the system observable before deciding where to block
The ant problem was frustrating because each visible entry point felt like the source.
The window looked like the source until it was fixed. The isolated spot across the apartment looked unrelated until the gel revealed the hidden path under the baseboards.
The lesson was not that gel is always better than spray. I actually ended up using spray in the end, on top of the gel, to speed up the process once we had a better understanding of where the ants were coming from. The important part was the order: observe first, understand the path, then apply the more direct response where it made sense.
Fraud detection has the same trap.
A fake account, an IP address, or a disposable email domain may look like the thing you need to eliminate. In many cases, they are better understood as places where the underlying campaign becomes visible.
The real source may be the account factory, the automation framework, the proxy provider, the email generation logic, the referral abuse network, or the operator’s process that ties everything together.
Good detection systems should help answer more than whether a specific entity should be blocked. They should also help answer what this entity revealed, what else is connected to it, which relationships are reliable enough to act on, and where a block would reduce harm instead of simply removing visibility.
That is the part I find interesting.
Blocking visible abuse is necessary, but it is not enough. If you only remove what you can see, you may keep fighting the same campaign forever, one account at a time.
Sometimes the better move is to make the system observable first, then decide where to spray.


